期刊: Mechanical Systems and Signal Processing(IF:8.4)
创新点
- 通过 JAM,可以自适应地提取更多的判别特征,从而增强对不同类别的判别能力。
- FTM 弥补了从特征提取器中提取的直接特征在少数样本中判别能力较弱的缺陷,它通过转移其他类别的通用泛化知识来增强直接特征,从而扩展了自身类别的特征空间。
方法
联合注意力模块
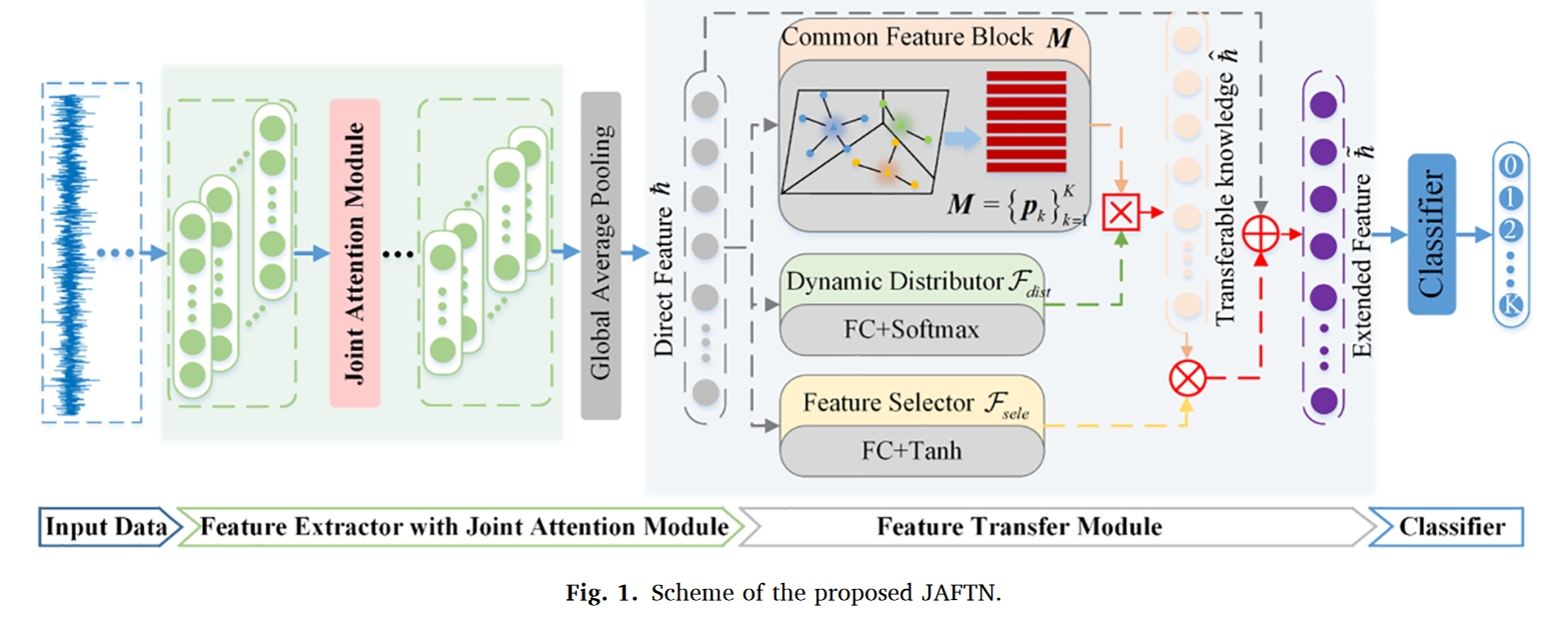
齿轮箱的振动信号是一维时间序列。轴承/齿轮的故障位置与旋转部件不断碰撞,产生周期性的故障脉冲激励和一系列高频衰减共振 [8,25]。因此,振动信号中故障激励信号段的位置显示了故障的固有特征。然而,同一类型故障产生的故障激励信号的位置周期性地出现在一维时间序列中,而不同类型故障产生的故障激励信号段则反映在一维时间序列的不同位置上。因此,提出了一种 PAM,使网络关注故障激励信号段的位置。此外,特征提取器提取的特征图由通道连接。不同通道对故障特征的贡献不同,有些通道可能包含较少甚至无效的故障特征信息[26]。具体来说,同一类别中不同通道的特征图的贡献度不同,而不同类别中特征图的同一通道具有区分不同故障类别的重要性。
因此,引入 CAM 来强调对故障特征信息贡献度高的通道,抑制贡献度低甚至无用的通道,从而从一维振动信号中提取更多的判别特征。因此,对于机械领域的一维振动信号,特征提取器提取的具有不同区分度的信息往往分布在特征的不同通道和不同位置。自适应地对这些位置进行联合关注,可能会使最终学习到的特征更容易区分其来自哪一类,从而使分类器更容易识别样本的类别,从而提高诊断性能。此外,需要说明的是,本文后面提出的 FTM 是基于类原型设计的。类原型是同一类别中所有特征向量的平均向量。优秀的原型表示取决于判别特征,最终的分类性能与类原型密不可分。如果能在特征提取阶段提取出更多能够区分不同类别的判别特征,生成的类别原型就能更好地代表不同类别的中心。这样,FTM 中更准确的类原型就能更有效地指导特征选择器和动态分配器的工作,从而提高网络性能。
特征迁移模块
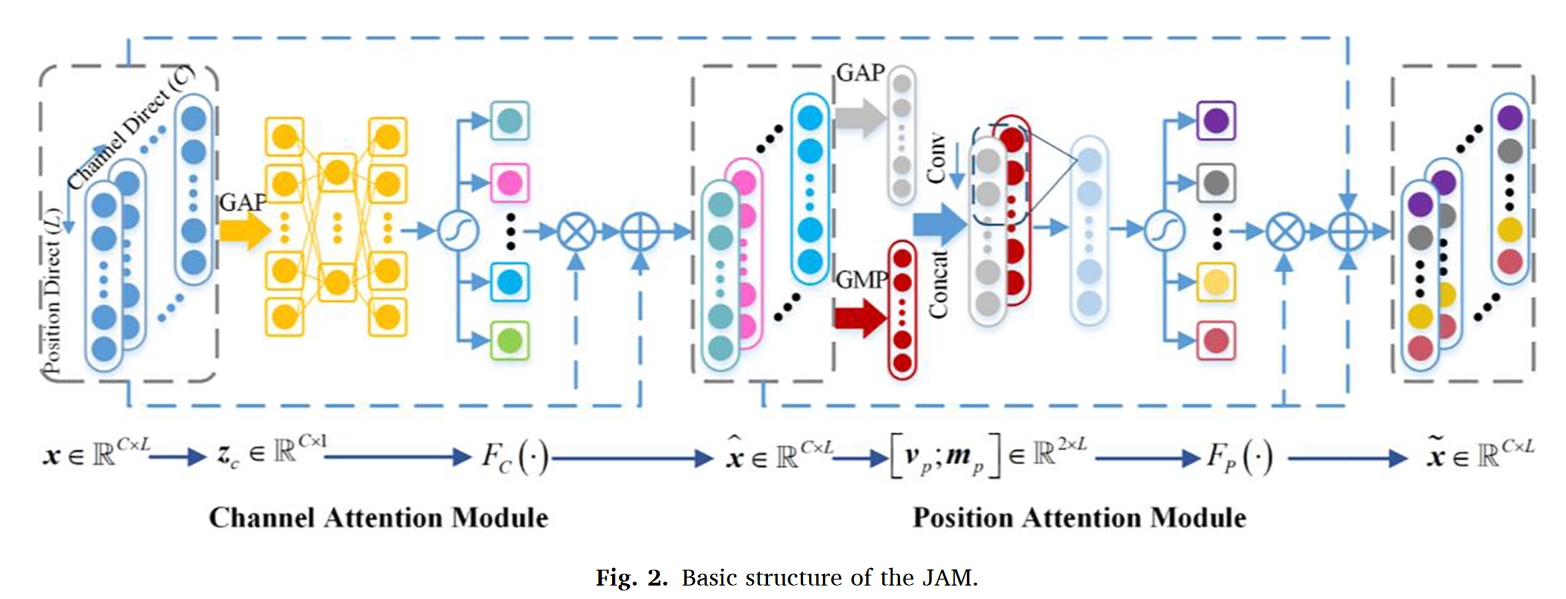
由于正常样本数量较多,特征提取器通常可以识别正常样本的特征并对其进行正确分类。然而,故障类样本相对较少,特征提取器不能很好地提取这些类的特征,缺乏对少量样本进行判别的能力,这就使得分类模型难以自适应地构建真实数据分布边界,导致模型严重偏差,对少量样本的故障类误诊率较高。
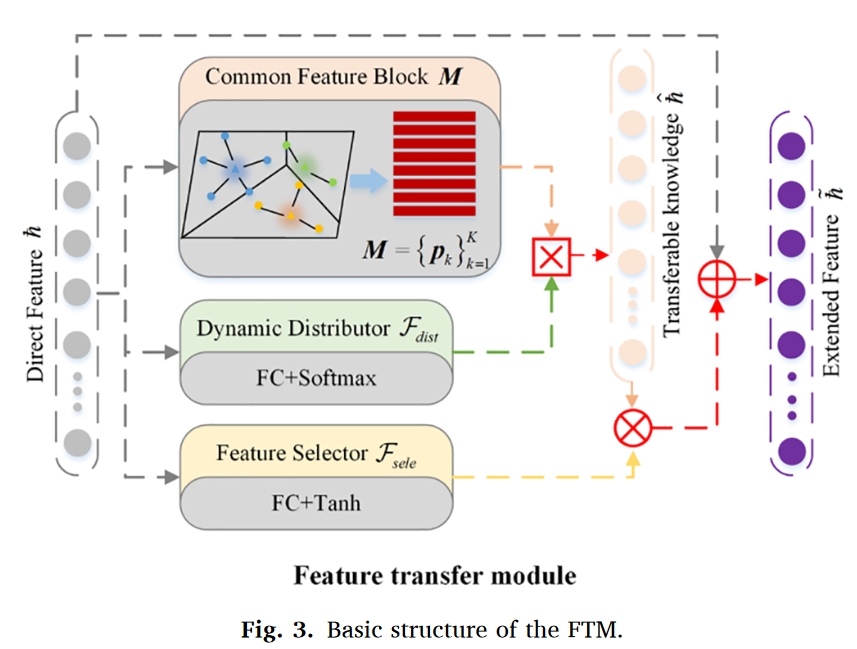
为了解决这个问题,我们提出了一种由多个轻量级神经网络和一个公共特征块组成的 FTM,以丰富从特征提取器中提取的直接特征的特征空间,其结构如图 3 所示。直接特征ħ被定义为由带有联合关注模块的特征提取器从原始一维振动信号中提取的特征。其位置如图 1 和图 3 所示,是特征转移模块的输入。每个类别的原型代表每个类别中所有直接特征向量的平均向量,可以大致代表每个类别的数据分布中心。
公共特征块 M 存储了每个类的原型,通过特征提取器的每个直接特征都会从公共特征块中吸收一些有用的泛化特征(即从其他类中转移公共特征),以补充当前的特征表示。特征选择器 $F_{sele}$ 的作用是控制知识吸收的程度,也就是说,对于样本较多的类别,特征提取器可以很好地进行表示,因此只需从公共特征块中转移少量知识。但是,对于样本稀少的类,由于特征提取器无法完全提取其特征,特征选择器就会以软阈值的方式从公共特征块中获取类似的泛化表示,以丰富自己类的特征空间。动态分配器 $F _{dist}$ 使用一个非线性网络,自适应地确定公共特征块中哪些类原型可以转移概括特征,以增强当前类的直接特征。
Optimization objective
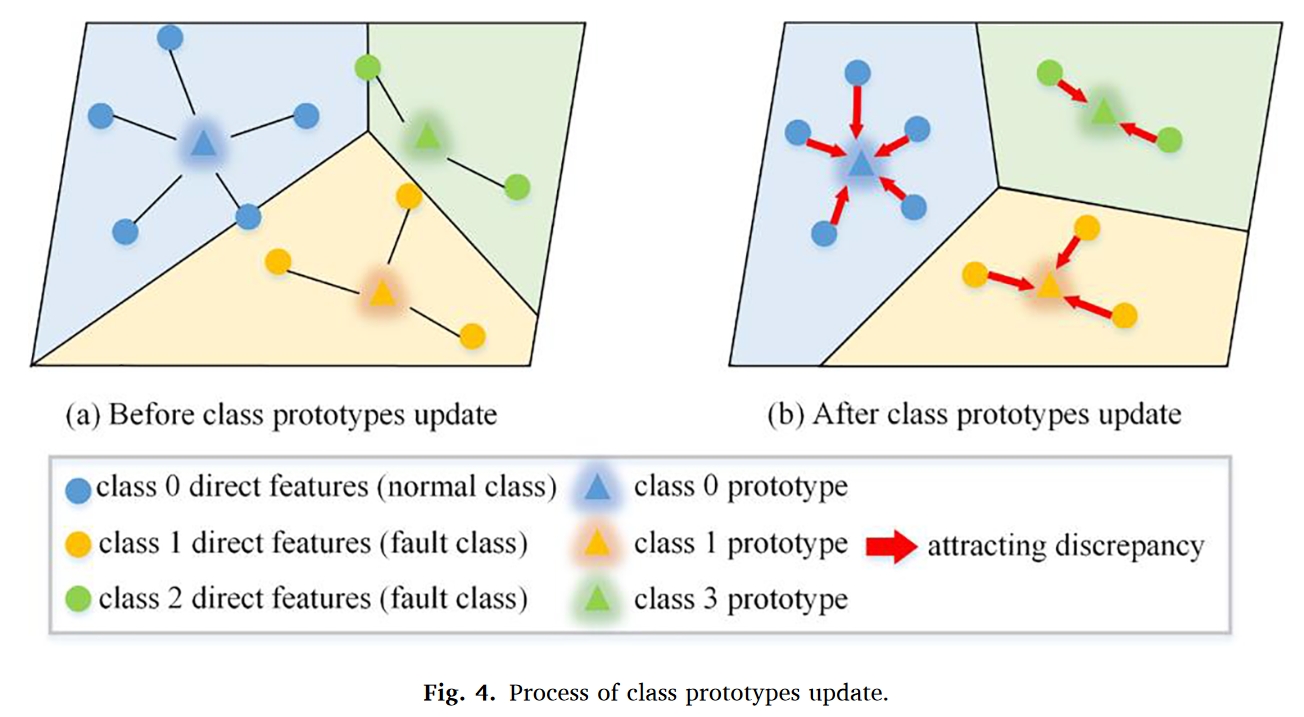
值得注意的是,公共特征块 M 是随着网络参数的不断更新而更新的。FTM 基于公共特征块工作,而公共特征块是由类别原型组成的。因此,一个能很好地代表每一类特征中心的原型对 FTM 的有效运行至关重要。从图 4 中可以看出,每个类的原型是该类所有直接特征向量的平均向量,大致代表了每个类的数据分布中心(图 4 (a))。通过最小化每个直接特征与类原型之间的距离,最终可以保持类内紧凑性,从而使类原型更好地代表每个类的数据分布中心(图 4 (b))。同时,类内紧凑性使决策边界更加明显,从而提高分类性能。因此,引入了边际差异损失(margin discrepancy loss),用欧氏距离作为度量每个直接特征与类原型之间距离的指标。
$L = L_{CE} + λ_{LMD}$
$L_{MD}(\hbar_i,{p_k}{k=1}^K)=\sum{y_i=k}\lVert\hbar_i-p_k\rVert_2^2$
$L_{CE}(\widetilde{\hbar},y_i)=-\frac1N\sum_{j=1}^Ny_i\mathrm{log}f\left(\widetilde{\hbar}_j\right)$
LCE 是扩展特$\widetilde{\hbar}_j$和类别标签 y 的交叉熵损失。
实验
数据集
- 齿轮数据集:自建
- Wind turbine gearbox dataset:A. Stetco, F. Dinmohammadi, X. Zhao, V. Robu, D. Flynn, M. Barnes, J. Keane, G. Nenadic, Machine learning methods for wind turbine condition monitoring: A review, Renew. Energy 133 (2019) 620–635.

对比方法
- WDCNN-2017-Sensors
- Re-sampling-(2017-TII)-(2018-Mech. Syst. Sig. Process)
- Focal loss-2021-TII
- SMOTE-2002-J. Art. Intell. Res.
- GAN-2020-Measurement
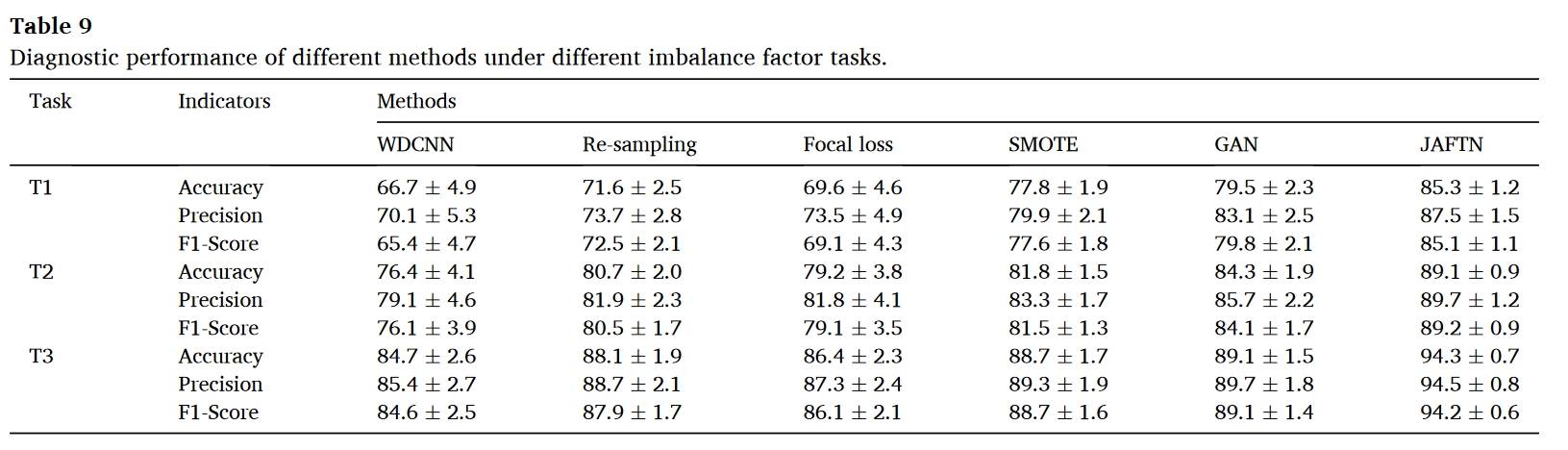
结果


总结
Transfer模块中的类型原型的思想(样本均值)的思想很点意思。
Chinnel Attention Module和Position Attention Module反而还比较常见。