期刊: Advanced Engineering Informatics(IF:8.8)
创新点
- 引入高斯引导分布对齐策略,使数据分布接近高斯分布,从而减少数据分布差异。
- 采用新型对抗训练机制进行领域适应,旨在通过考虑类别边界来识别目标数据。
方法
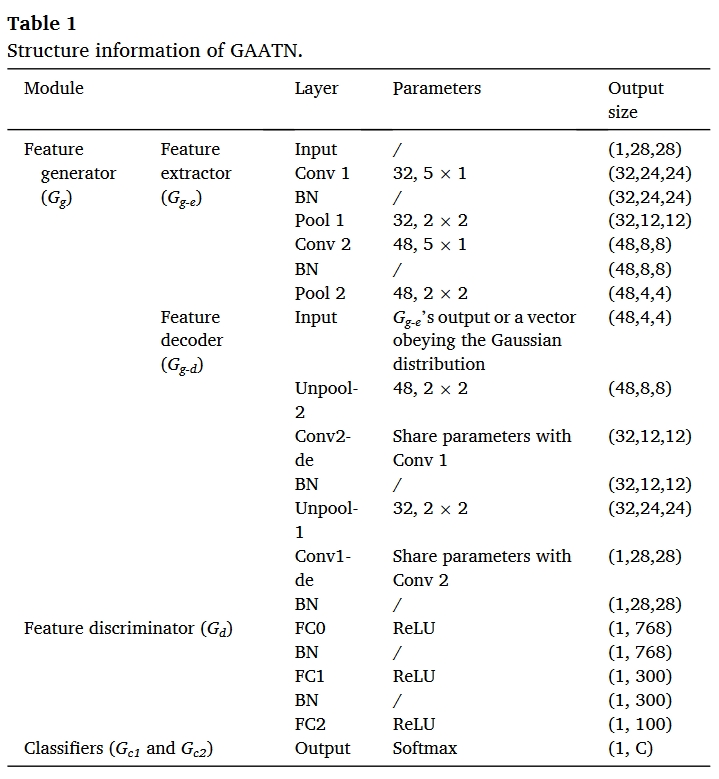
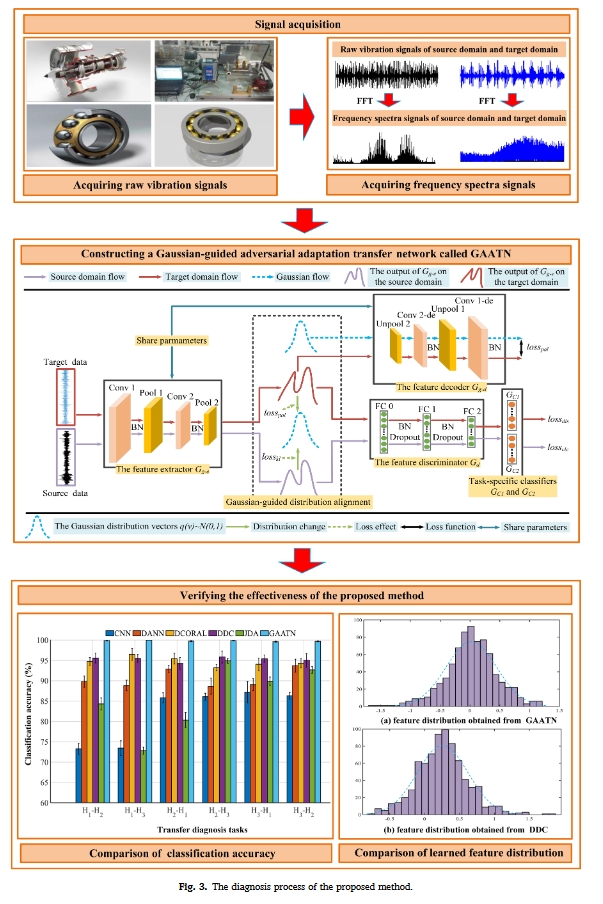
在高斯分布的指导下,为了有效地调整数据分布并考虑目标数据与类别边界之间的关系,本文提出了一种名为 GAATN 的无监督方法。图 1 介绍了 GAATN 的具体架构。如图 1 所示,本文提出的 GAATN 包括一个特征生成器(Gg)、一个特征判别器(Gd)和两个特定任务分类器(Gc1 和 Gc2)。GAATN 的结构信息如表 1 所示。值得强调的是,表 1 中的所有参数都是根据文献[26,28]和实验确定的,以获得令人满意的识别结果。本节将详细介绍 GAATN 的训练过程。
特征提取器
两层CNN
特征判别器和特定任务分类器
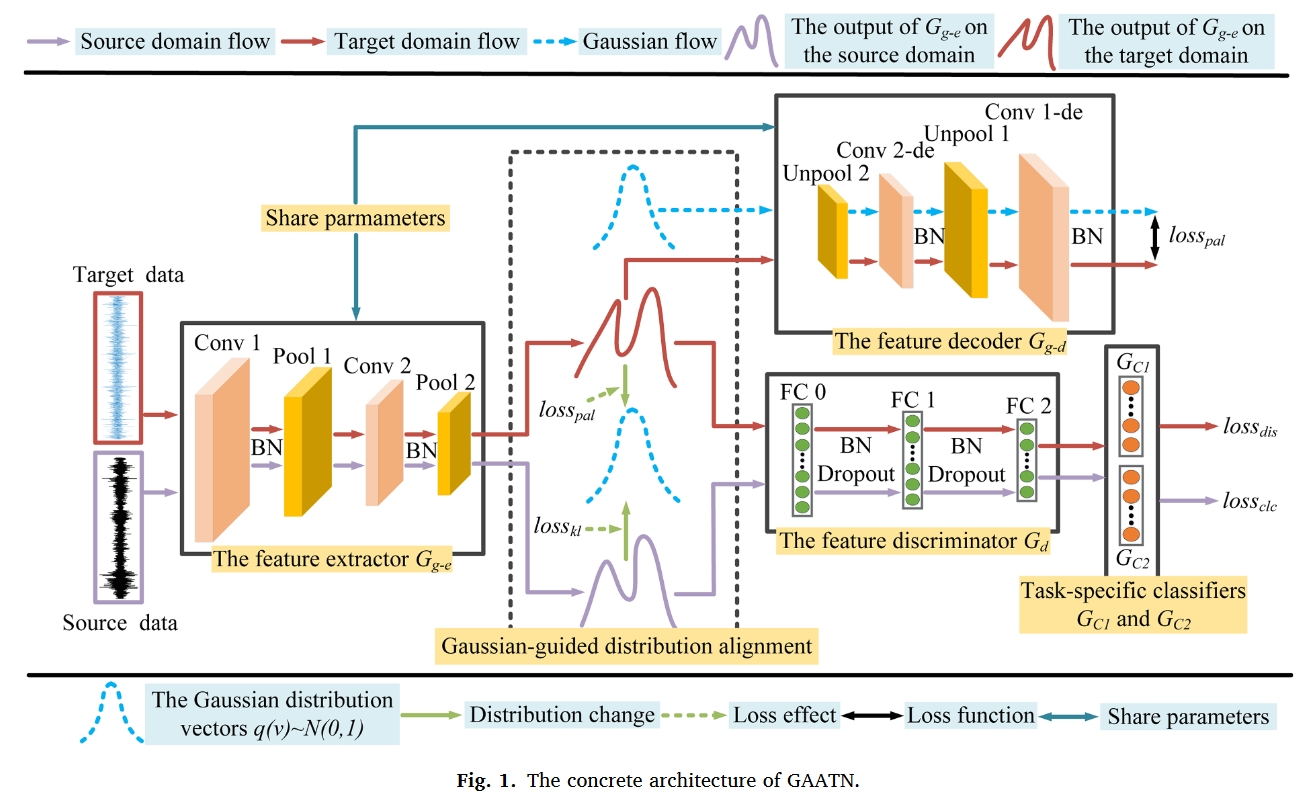
如图 2(a)所示,在一般的域自适应方法中,分类器可以在 DS 中很好地工作,但是,这些方法在决策边界附近的目标数据上的识别性能会降低。
如图 2 (b)所示,与一般的领域适应方法不同,GAATN 设计了两个特定任务分类器(Gc1 和 Gc2)来考虑类别决策边界。具体来说,Gc1 和 Gc2 的目标是准确地对带有标签的源数据进行分类,并同时训练它们识别远离源域支持的目标数据。
请注意,Gc1 和 Gc2 的初始化是不同的,从训练一开始就使用 dropout 获得不同的分类器。然后得到 Gc1 和 Gc2 对目标数据的预测分歧。为了识别远离源域支持的目标数据,首先要使分歧最大化,这一操作将在 3.4 的步骤 2 中介绍。GAATN 的对抗训练机制。如果不进行这一操作,Gc1 和 Gc2 可能会非常相似,无法识别远离源域支持的目标数据。这种分歧使得 Gg 能够在源域支持范围内生成目标特征表征。通过 Gg 和 Gd 之间的博弈,分歧最终将被最小化,这一操作将在 3.4 的步骤 3 中介绍。GAATN 的对抗训练机制。双分类器之间的分歧描述如下:
$Dis(p_1(y|x^T),p_2(y|x^T))=\frac1C\sum_{c=1}^C\lvert p_{1,c}-p_{2,c}\rvert $
其中,$Dis(p_1(y|x^T),p_2(y|x^T))$是两个分类器在目标数据 $x^T$ 上的分歧,$p_1(y|x^T)$和 $p_2(y|x^T)$分别代表 $G_{c1}$ 和 $G_{c2}$ 对目标数据 xT 的输出。$p_{1,c}$ 和 $p_{2,c}$ 代表类别 c 的输出概率。
GAATN 的优化目标
本节将讨论 GAATN 的优化目标。在高斯分布的指导下,GAATN 采用三个步骤实现更好的域适应。
定义高斯分布 q(v)∼ N(0,1)。为了确保源数据能被正确分类,我们选择了广泛使用的交熵损失函数 $loss_{clc}$ 来表示两个特定任务分类器对源数据的识别能力。为了鼓励特征提取器 $G_{g-e}$ 生成的源特征表示接近 $q(v^S)$,我们为 $G^{g-e}$ 选择了 KL-发散函数 $loss_{kl}$ 来衡量两个分布之间的差异。
$\begin{aligned}
&loss_{clc}\big(x^{s},y^{s}\big)=loss_{clc}\big(output_{1}^{s},y^{s}\big)+loss_{clc}\big(output_{2}^{s},y^{s}\big) \
&=-\frac1{n^s}\left[\left(\sum_{i=1}^{n^s}\sum_{c=1}^CI\left[y^{s_i}=c\right]\mathrm{log}p_{1,c}(y|x^{s_i})\right)\right. \
&\left.+\left(\sum_{i=1}^{n^s}\sum_{c=1}^CI\left[y^{s_i}=c\right]\mathrm{log}p_{2,c}\left(y|x^{s_i}\right)\right)\right] \
&loss_{kl}\big(x^{s}\big)=\frac1{n^{s}}\sum_{i=1}^{n^{s}}q\big(\nu^{s_{i}}\big)\mathrm{log}\frac{q(\nu^{s_{i}})}{G_{g-e}(x^{s_{i}})}
\end{aligned}$
其中$lossclc(x^S,y^S)$是两个分类器对源数据的分类损失。nS表示DS的总数。outputS1和outputS2分别表示Gc1的输出Gc1(Gd(Gg e(xS))和Gc2的输出Gc2(Gd。I[.]表示指标函数。q(vSi)是具有高斯分布的第i个矢量。Gg-e(xSi)表示Gg-e对于输入xSi的输出。
为了在考虑决策边界的情况下有效识别 DS 支持排除的目标数据,将对两个分类器 Gc1 和 Gc2 进行训练,使 $x^T$ 的分歧最大化。目标描述如下。
$loss_{dis}(x^T)=Dis(p_1(y|x^T),p_2(y|x^T))$
训练特征解码器 Gg-d 来编码由 Gg-e 生成的目标特征表示和高斯分布 q(vT)。成对配准损失(losspal)用于计算目标特征分布与高斯分布之间的差值,从而使两个分类器对 $x^T$的分歧最小化:
$loss_{pal}(x^T)=\frac1{n^T}\sum_{j=1}^{n^T}\left|G_{g-d}(G_{g-e}(x^{T_j}))-G_{g-d}(q(\nu^{T_j}))\right|_1$
其中,$n^T$ 是 $D^T$ 总数。$||.||_1$ 是 L1 准则。
GAATN的训练过程
根据上面介绍的这些优化目标,可以从模块结构上解释 GAATN 的对抗训练机制的新颖性:与一般对抗适应方法的特征发生器不同,GAATN 的特征发生器分为特征提取器和特征解码器。
特征提取器的作用是将输入数据编码到潜在特征空间中,特征解码器则对特征提取器中的特征进行解码或对高斯向量进行解码。这种编码和解码操作可以促使数据分布接近高斯分布。
特征判别器旨在区分特征来源,避免被特征生成器欺骗。与一般对抗自适应方法的分类器相比,GAATN 的特点是设计了两个特定任务分类器来考虑每个数据类别的特征,这有利于正确识别这些远离源支持的目标数据。
在 GAATN 中,特征提取器和特征解码器的特征生成器、特征判别器以及两个特定任务分类器都是经过训练来实现相应功能的。由于模块构成不同,GAATN 的对抗训练机制也不同于一般的对抗适应方法。GAATN 的对抗训练机制的实现过程可以概括为以下三个步骤。
- 更新 Gg-e、Gd、Gc1 和 Gc2,以便在高斯分布的指导下准确识别源数据。
- 固定 Gg-e,更新 Gd、Gc1 和 Gc2,使源数据上的识别误差最小,目标数据上的双分类器输出差异最大。
- 固定 Gc1 和 Gc2,更新 Gg-e 和 Gg-d,以最小化目标数据上 Gc1 和 Gc2 两项输出之间的差异。该步骤强制目标特征分布接近高斯分布,以识别目标数据。
GAATN 的对抗训练机制不需要标注目标数据参与训练。当输入所有数据时,在每个 epoch 中,这三个步骤将依次执行。完成这三个步骤后,将分别获得源数据和目标数据的识别准确率。在所有epoch结束后,将输出目标数据的识别准确率。通过增加epoch次数,GAATN可以使两个域的特征分布与高斯分布一致,从而实现目标诊断任务。
实验
数据集
- rotor:K.e. Li, M. Xiong, F. Li, L. Su, J. Wu, A novel fault diagnosis algorithm for rotating machinery based on a sparsity and neighborhood preserving deep extreme learning machine, Neurocomputing 350 (2019) 261–270.
- CWRU
对比方法
- CNN
- DANN-2020-TIE
- DCORAL-2007-ACM MM
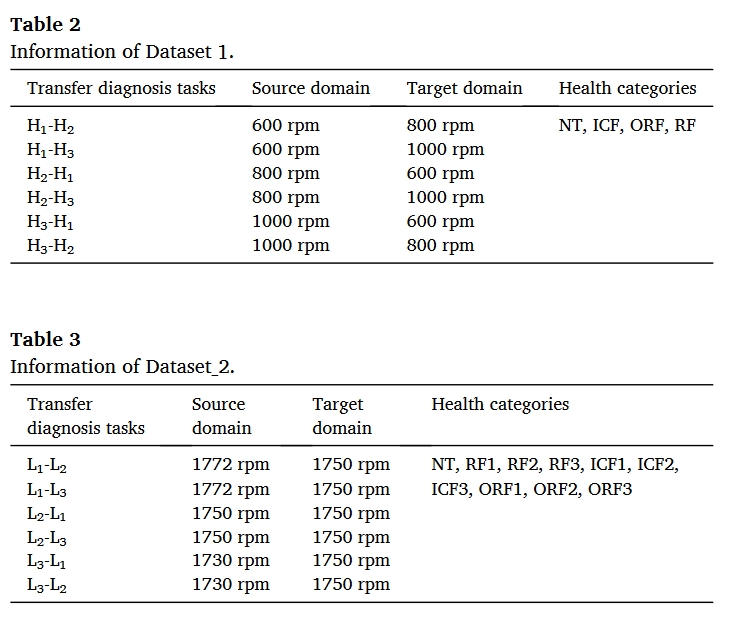
结果
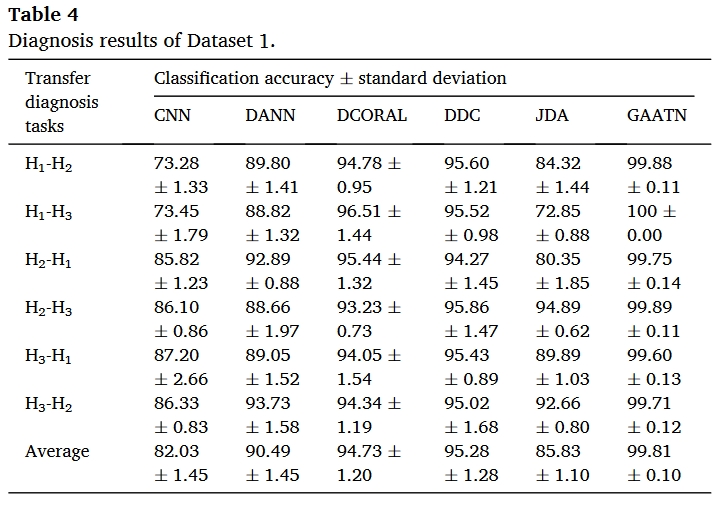
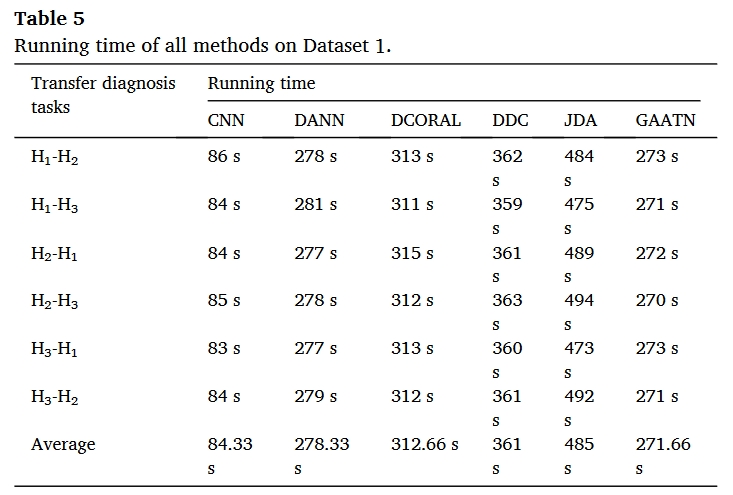
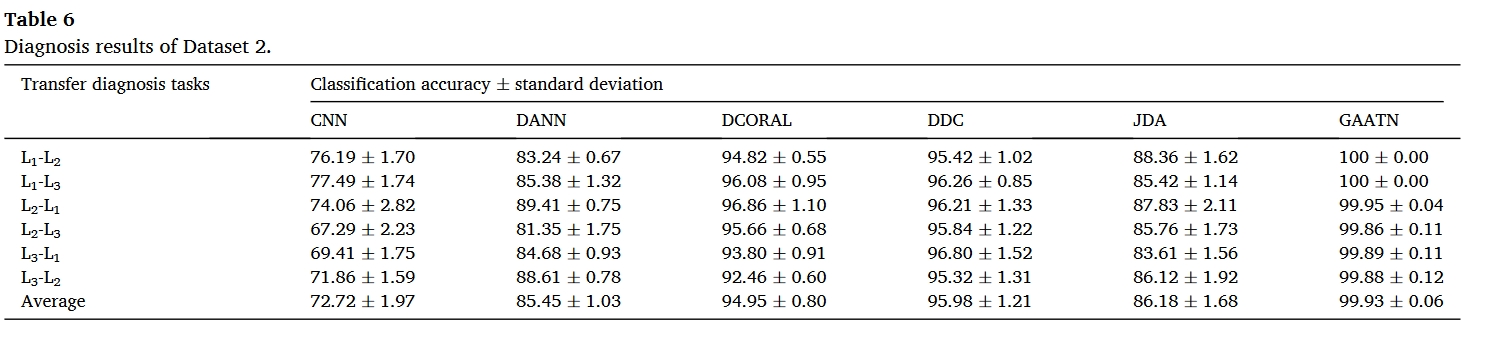
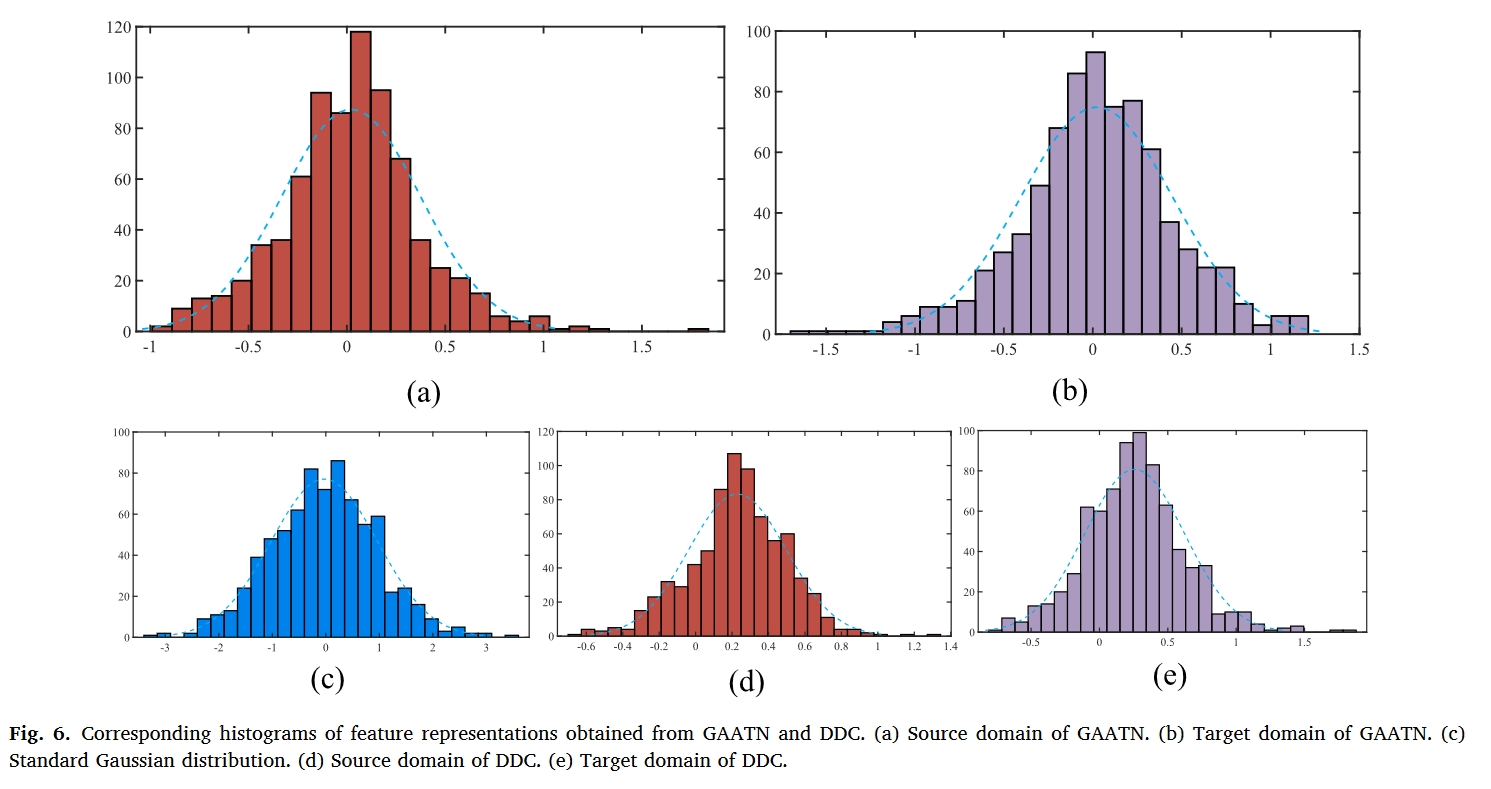
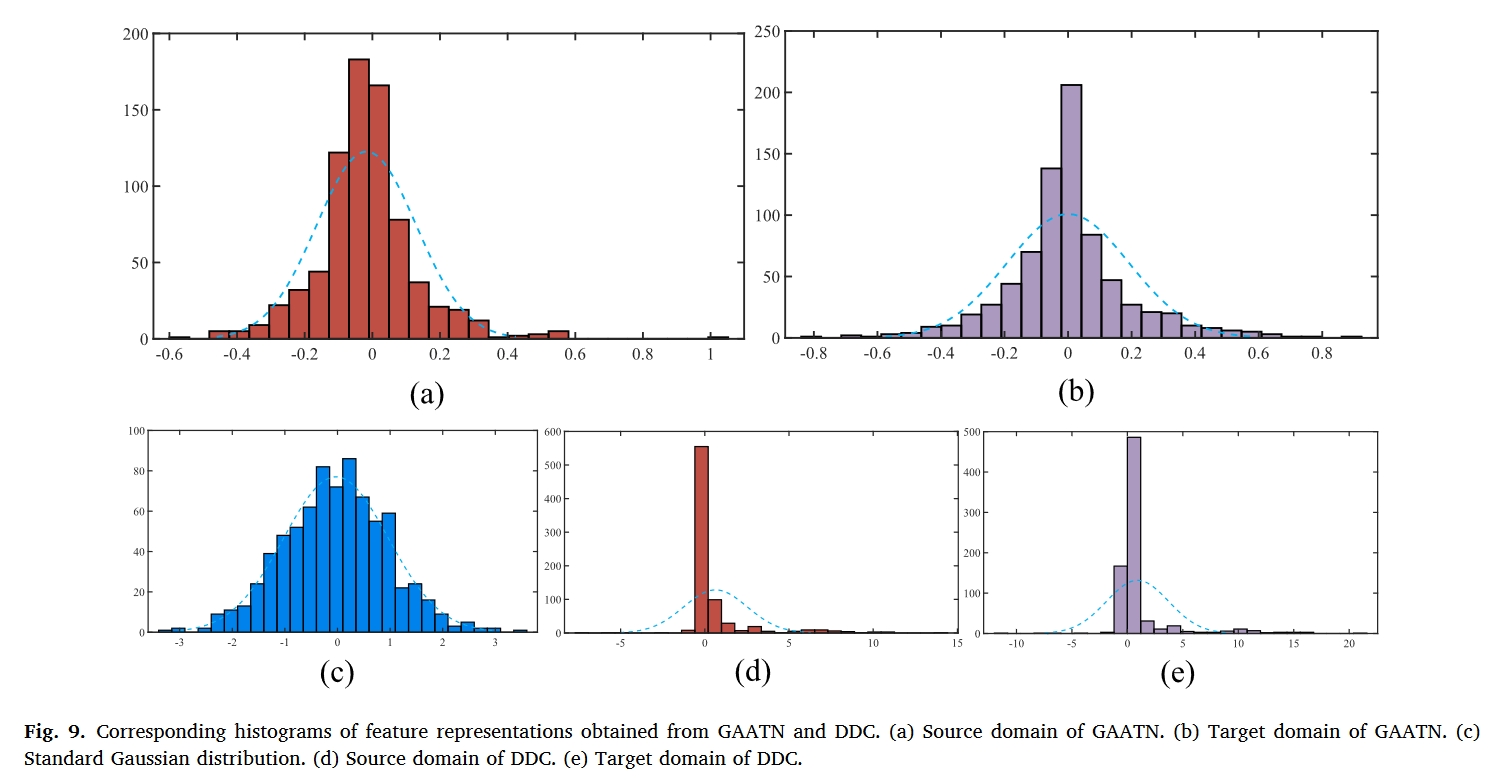
总结
- 高斯指导的思想第一次见
- 两个分类器的思想也还可以,但是都有SAN了,emmm