期刊: Engineering Applications of Artificial Intelligence(IF:8)
创新点
- 所提出的 ES-SAN 模型主要针对现有部分 DA 诊断研究中的两个局限性:基于单一人工智能模型的分类器由于泛化性能有限而容易产生负迁移;设置多个子域判别器的学习框架在处理多个源类时会导致模型过于复杂。本文的探索有助于构建一个新颖的部分 DA 框架来解决跨域诊断问题。
- ES-SAN中设计了一个集合共享模块,通过Dempster-Shafer(DS)理论(Yager,1987)由多个共享模块组成,整合了不同人工智能模型的学习特性,能够为目标样本的转移提供更可靠的指导。此外,每个共享模块都包含一个相关层,使模块能够在分类器和能够进行多子域判别的判别器之间进行转换,从而形成一个简化的部分检测框架,以降低处理多源类别时的模型复杂度。
相关技术
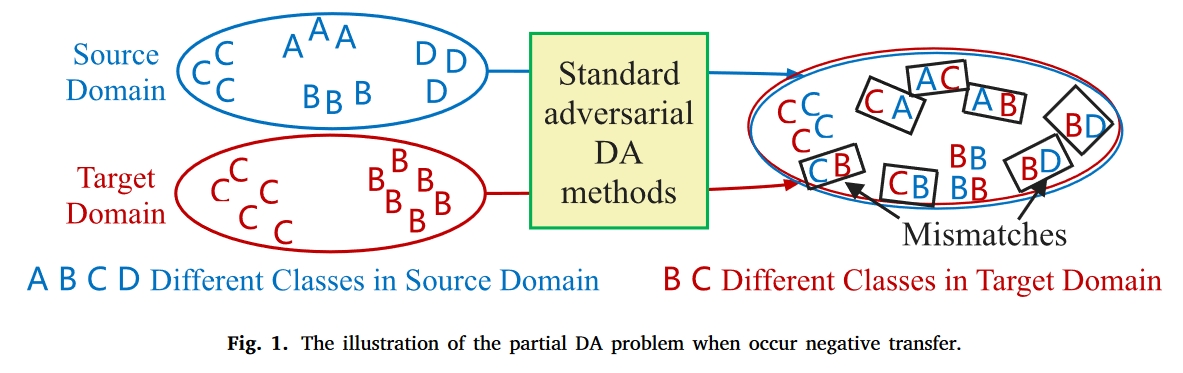
部分 DA 问题最早是在计算机视觉领域提出的(Cao 等人,2018 年),指的是目标域只覆盖源类的一个子集的情况。为了解决无监督的部分 DA 问题,人们通过在标准 DA 网络中嵌入加权策略提出了许多模型(You 等,2019;Wang 等,2018b;Hu 等,0000),如示例转移网络(Cao 等,2019)、动态对抗适应网络(DAAN)(Yu 等,2019)和重要性加权对抗网络(IWAN)(Zhang 等,2018)。Zhao 等人(2022)讨论了针对视觉任务的不同类型的单源无监督 DA 方法,其中领域对抗训练被认为是目前主流的 DA 策略。在SAN(Cao等人,2018)中,构建了一个具有多子领域判别器的部分DA框架,其中每个判别器对应一个源类,所有判别器对齐不同权重,以有效匹配来自共享类的样本。该框架为局部 DA 提供了一种经典的域对抗学习方式,因此在机械故障诊断中也被广泛采用。通过将领域预测损失与离群类置信度联系起来,Li 等人(2020b)提出了一种类加权对抗神经网络,对源样本进行重新加权,使其更加关注共享类。在 Deng 等人(2021 年)的研究中,构建了一个双关注矩阵,用于在训练每个判别器时选择子域判别器和目标样本。然而,这些现有方法有两个局限性:
分类器仅依赖于单一的人工智能模型,其泛化能力可能不足以识别所有潜在的目标类别,因为其知识是通过单一的学习方式分布在一组神经元上的(Li 等人,2020b;Deng 等人,2021)。因此,预测的结果可能并不可靠,在用于模型训练时会导致负迁移。
对于源类较多的 DA 诊断任务,盲目增加子域判别子会导致整个 TL 模型过于复杂。
这项研究主要受到SAN模型(Cao等人,2018)和集合学习(Hansen和Salamon,1990)的启发。在集合学习中,通过 DS 理论或其他规则,将不同的人工智能模型组合成一个强大的学习模型,克服了泛化能力有限的困境。因此,本文旨在开发一种新型的部分 DA 故障诊断模型,以克服上述两个局限性。具体来说,有以下两点改进:
- 该分类器集成了不同的人工智能算法,在识别目标类方面比现有方法具有更强的泛化能力。
- 分类器和领域鉴别器共享一个模型架构,形成了一个简化的部分DA框架,以降低集成不同AI模型以处理多个源类的模型复杂性。
SAN—Partial Transfer Learning with Selective Adversarial Networks
SAN将共享类别空间中的源域样本分布和目标域样本分布对齐,更重要的是,将源域中非共享类别中的样本分离。与以前的方法相比,该方法一个关键的改进是能够同时促进相关数据的正向迁移和减轻不相关数据的负向迁移,还可以在端到端框架中进行训练。
由于源域的非共享类别$C_s$/$C_t$会造成负迁移,所以要将属于非共享类别的样本分离。
作者将域分类器分为$|C_s|$个类别级的域分类器$G^k_d,k=1,..,|C_s|$,每个分类器负责类别为k的源域样本与目标域样本的匹配。但是由于目标域的样本未标注,所以对于一个目标域的样本来说,我们不知道应该使用哪个域分类器$G^k_d$。于是作者将类别预测器$\hat{y}_i=G_y(x_i)$的输出作为该目标域样本$x_i$属于对应源域类别空间$C_s$中某个类别的概率。
即可以使用$y_i$的输出来表示每个目标域样本使用$|C_s|$个域分类器$G^k_d$的概率。这个概率加权域鉴别器损失为:
$L’d=\frac{1}{n_s+n_t}\sum\limits^{|C_s|}\limits{k=1}\sum\limits_{x_i\in D_s\cup D_t}\hat{y}_i^kL^k_d(G^k_d(G_f(x_i)),d_i)\$
与公式(1)中的单一域分类器相比,这里的多级域分类器拥有细粒度适应性,这个细粒度适应性拥有以下好处:
- 它避免了将每个样本强硬分配给一个域分类器,这对于目标域样本来说往往是不准确的
- 它避免了负迁移,因为每个样本只与一个或几个最相关的类对齐,而不相关的类被概率加权域分类器损失过滤掉
- 概率加权域分类器损失将不同的损失放在不同的域分类器上,它自然地学习具有不同参数$\theta^k_d$的多个域分类器;这些具有不同参数的域分类器可以促进每个样本的正向迁移。
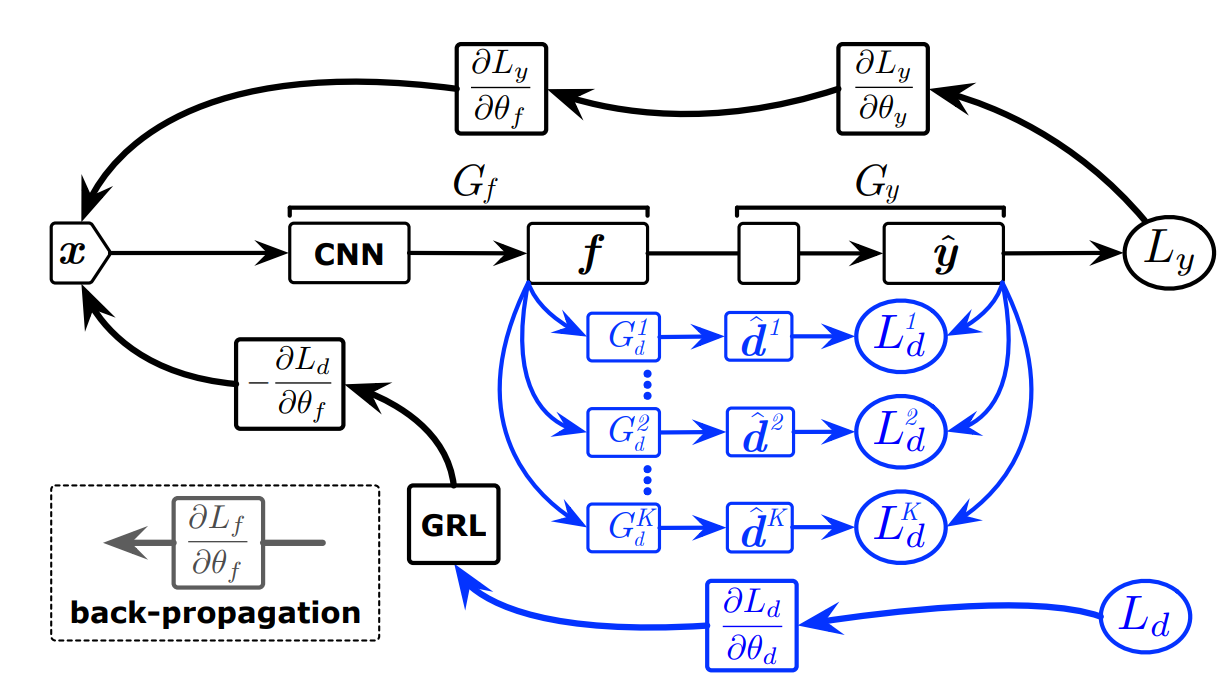
SAN模型架构图:其中f表示提取出来的特征,$\hat{y}$表示预测的样本标签,$\hat{d}$表示预测的域标签,$G_f$表示特征提取器,$G_y$与$L_y$表示标签预测器与其损失,$G^k_d$与$L^k_d$表示域分类器和它的损失。蓝色部分表示类别级对抗网络。
作者观察到只有负责目标域类别的域分类器对促进正迁移有效,而其他负责源域非共享类别的分类器仅引入噪声并恶化共享类别空间中源域和目标域之间的正迁移。因此,需要对负责源域非共享类别的域分类器进行降权,这可以通过对这些域分类器进行类级权重衡量来实现。
方法
本文在以下假设条件下对部分 DA 故障诊断进行研究:
- 源域 $D_s = {(x_i, y_i)}^{n_s}{i=1}$ 和目标域 $D_t = {x_i}^{n_t}{i=1}$ 中分别有 $n_s$ 个标记样本和 $n_t$ 个未标记样本。目标样本只覆盖源域$ C_t∈C_s$ 中的故障类子集,因此存在一些离群源类 $Cs∕Ct$,这将导致负转移。
- 由于实际诊断中考虑的故障较多,源类|Cs|的数量较大,因此不可避免地要在多个子域中对每个样本 xi 进行判别。
- 除了领域分布差异外,所有类别中的故障样本在特征空间中严重重叠,因此一些潜在的目标类别很难被识别,这是因为每个人工智能算法都有自己的能力领域,可能不适合学习这些特征(Wolpert,2002)。
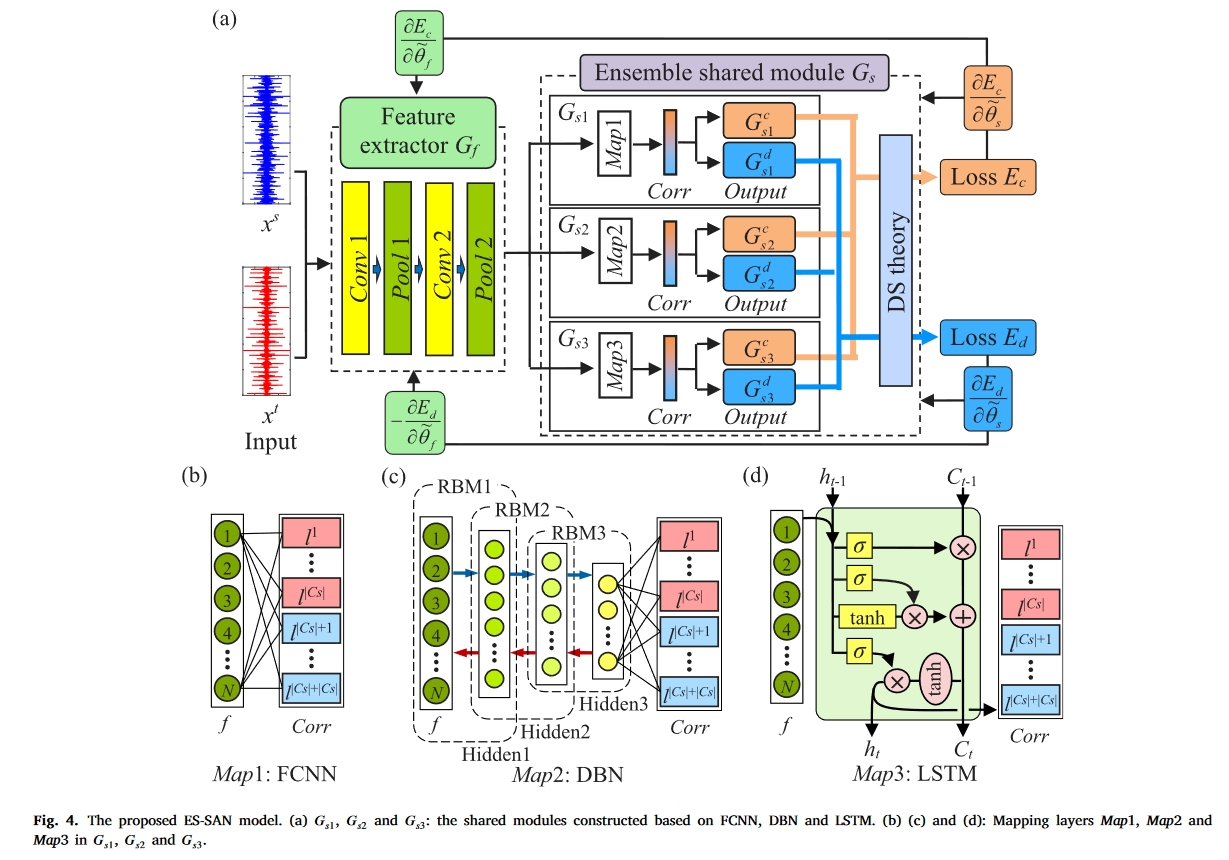
为了在给定的假设条件下实现部分 DA 诊断任务,我们开发了一种新颖的 TL 模型 ES-SAN,它由两个模块组成:特征提取器,旨在从源样本和目标样本中提取领域不变的特征;集合共享模块,由三个基于不同人工智能模型的共享模块组成,旨在对提取的特征进行分类和判别,每个共享模块用一个简化的学习框架替代分类器和多个子领域判别器。
带共享模块的改进型 SAN
在部分判别问题中,样本类的数量等于子域的数量,每个子域的判别都是二元分类任务。直观地说,如果分类器与判别器共享其模型参数,就可以在一个模型上实现多子域判别,从而简化部分 DA 框架。
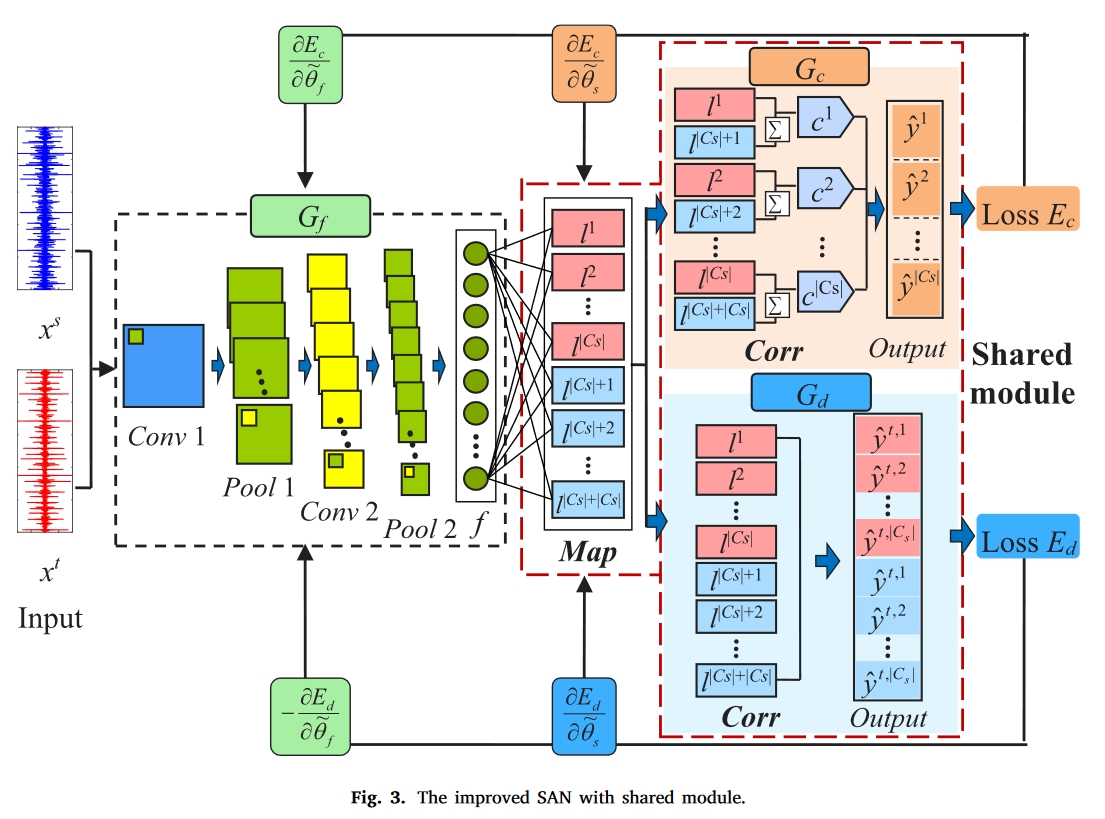
因此,我们首先提出了一种带有共享模块的改进型 SAN(S-SAN),它包含一个特征提取器 Gf 和一个共享模块,可以在分类器 Gc 和域判别器 Gd 之间进行转换,从而实现多子域判别,如图 3 所示。Gf 是经典的二维 CNN 架构(Wang 等,2018a),由两个卷积层(Conv1 和 Conv2)和两个池化层(Pool1 和 Pool2)组成,用于提取域不变特征。共享模块由映射层 Map、相关层 Corr 和 Softmax 输出层 Output 组成,用于给出每个样本的类和域概率。
带相关层的共享模块
映射层 Map 对应于无激活的全连接层,因此共享模块可以看作是带有新颖相关层 Corr 的全连接神经网络(FCNN)。具体来说,Corr 是一个具有 2⋅|Cs| 节点的隐藏层,这意味着每个样本的域不变特征被映射成一个具有 2 ⋅|Cs| 元素的向量:
$\begin{array}{l}f_i=G_f(x_i)\L_i=Map(f_i)=[l_i^s,\quad l_i^t]\l_i^s=[l_i^{s,k}],\quad l_i^t=[l_i^{t,k}],\quad k=1,2,\ldots,|C_s|\end{array}$
其中,$𝑓_𝑖$表示在ᵃ𝑓中提取的样本$𝑥_𝑖$的域不变特征,$𝐿_𝑖 = 𝑀𝑎𝑝(𝑓_𝑖)$表示将𝑓映射到 Corr 中,以获得包含完整特征信息的向量。在$𝐿_𝑖$中,$𝑙_i^{s,𝑘}$ 和 $𝑙^{𝑡,𝑘}_𝑖$ 表示分别反映$𝑥_𝑖$ 来自属于 k 类的源域和目标域的特征信息。因此,Corr 中的𝐿𝑖 可用于分类和域区分。
共享模块转换为分类器
由于 Corr 包含样本的类信息和域信息,因此共享模块中的分类器和判别器都是通过自适应地关联这两类信息来构建的。具体来说,在分类阶段,向量 𝐿𝑖 将被转换为
$\begin{aligned}C_i&=Corr(L_i)\&=[c_i^k]=[l_i^{s,k}+l_i^{t,k}],\quad k=1,2,\ldots,|C_s|\end{aligned}$
其中,𝐶𝑖 是 Corr 在对样本 𝑥𝑖 进行分类时的输出向量。在𝐶𝑖中,$𝑐^𝑘_𝑖 = 𝑙^{𝑠,𝑘}_𝑖 + 𝑙^{𝑡,𝑘}_𝑖$ 表示属于 k 类的领域信息和目标域信息是相关的,其中如果𝑥𝑖 来自 k 类,则$𝐶_𝑖$ 最大。在 “输出 “中,向量𝐶𝑖通过 Softmax 回归被进一步激活。
$G_c(C_i)=\frac{1}{\sum_{k=1}^{|C_s|}\exp(c_i^k)}\exp[c_i^k]=[\hat{y}_i^k],\quad k=1,2,\ldots,|C_s|$
其中 $\hat{𝑦}^𝑘_𝑖$ 是表示 𝑥𝑖 属于类别 k 的概率输出,即第𝑘 个类别概率输出。因此,𝐺𝑐(𝐶𝑜𝑟(𝑀𝑎𝑝(𝐺𝑓 (𝑥𝑖)))))被视为计算每个样本的类概率权重。
共享模块转换为域鉴别器
对于多子域判别,实际上是要区分属于同一类别的源样本和目标样本,因此,𝐿𝑖 的类别和域信息在 Corr 中不再相关,而是直接在输出层 Output 中激活。
$\begin{aligned}
G_{d}(L_{i})& =\frac{1}{\sum_{k=1}^{|C_{s}|}\exp(l_{i}^{s,k})+\exp(l_{i}^{t,k})}\left[\exp[l_{i}^{s,k}],\quad\exp[l_{i}^{t,k}]\right] \
&=[\hat{y}{i}^{s},\quad\hat{y}{i}^{t}] \
&\hat{y}{i}^{s}=[\hat{y}{i}^{s,k}]\quad\hat{y}{i}^{t}=[\hat{y}{i}^{t,k}],\quad k=1,2,\ldots,|C_{s}|
\end{aligned}$
其中$\hat{y}^{s,k}_i$ 和$\hat{y}^{t,k}_i$ 分别是表示𝑥𝑖 来自属于类别 k 的源域和目标域的域概率输出。可以看出,𝐺𝑑 (𝐿𝑖)是完整的概率向量,包含每个子域中𝑥𝑖的域概率。因此,𝐺𝑑 (𝑀𝑎𝑝(𝐺𝑓 (𝑥𝑖))) 可以被视为能够进行多子域判别的域判别器。
从第 4.1.2 节和第 4.1.3 节可以看出,分类和多子域判别都是在这个共享模块上实现的,它构成了一个简化的部分 DA 框架。直观地说,以标准 FCNN 的形式对 N 维特征向量进行分类和判别时,只需要训练 2𝑁 ⋅ |𝐶𝑠| 权重,如表 1 所示。然而,由于分类器和判别器需要分别建模,因此在 SAN 中需要 3𝑁 ⋅ |𝐶𝑠| 权重,如表 2 所示。因此,这个共享模块减少了模型参数,这对于有许多源类别的诊断任务来说意义重大。
目标函数优化
分类器𝐺𝑐(𝐶𝑜𝑟(𝑀𝑎𝑝(𝐺𝑓(𝑥𝑖)))))的分类损失可求得:
$\begin{aligned}
E_{c}& =\frac{1}{n_{s}}\sum_{x_{i}\in D_{s}}L_{y}(G_{c}(Corr(Map(G_{f}(x_{i})))),y_{i}) \
&+\frac{1}{n_t}\sum_{x_i\in D_t}H(G_c(Corr(Map(G_f(x_i)))))) \
&=-\frac{1}{n_{s}}\sum_{x_{i}\in D_{s}}\sum_{K=1}^{|C_{s}|}y_{i}^{k}\log(\hat{y}{i}^{k}) \
&-\frac1{n_t}\sum{x_i\in D_t}\sum_{K=1}^{|C_s|}\hat{y}_i^k\log(\hat{y}_i^k)
\end{aligned}$
其中,$𝑦^𝑘_𝑖$ 表示类别 k 上 𝑥𝑖 的真实标签$\hat{𝑦}^𝑘_𝑖$ 是第𝑘个类别概率输出。条件熵损失𝐻(⋅)用于进一步修正分类器𝐺𝑐,以最小化获取目标样本时的预测不确定性。
由于判别器ᵃ𝑑 的输出包含每个类别中的域概率,因此可以直接获得概率权重,将目标样本分配到不同的子域中。因此,域对抗损失𝐸𝑑 如下:
$\begin{aligned}
E_{d}& =\frac{1}{n_{s}}\sum_{x_{i}\in D_{s}}L_{d}(G_{d}(F(G_{f}(x_{i}))),y_{i}) \
&+\frac{1}{n_{t}}\sum_{x_{i}\in D_{t}}L_{d}(G_{d}(F(G_{f}(x_{i}))),\hat{y}{i}^{t}) \
&=-\frac1{n{s}}\sum_{x_{i}\in D_{s}}\sum_{k=1}^{|C_{s}|}P_{k}\cdot\left(y_{i}^{k}\log(\hat{y}{i}^{s,k})\right) \
&-\frac{1}{n{t}}\sum_{x_{i}\in D_{t}}\sum_{k=1}^{|C_{s}|}P_{k}\cdot\left(\frac{\hat{y}{i}^{t,k}}{\sum{K=1}^{|C_{s}|}\hat{y}{i}^{t,K}}\log(\hat{y}{i}^{t,k})\right) \
&P_{k}=\frac{1}{n_{t}}\sum_{x_{i}\in D_{t}}\hat{y}{i}^{s,k}+\hat{y}{i}^{t,k}\quad\hat{y}{i}^{t}=[\hat{y}{i}^{t,k}],\quad k=1,2,\ldots,|C_{s}|
\end{aligned}$
An ensemble and shared SAN
上述部分诊断过程高度依赖于类和域概率输出,而共享模块仅依赖于单一人工智能模型,因此将样本分配到不同子域的概率权重可能不可靠(Wolpert,2002)。为应对这一挑战,上述 S-SAN 进一步改进为集合共享 SAN(ES-SAN),如图 4(a)所示。在这个网络中,基于不同人工智能模型的多个共享模块通过 DS 理论被组合成一个集合共享模块,它可以为指导目标样本的转移提供可靠的权重。
实验
数据集
- CWRU
- 自建
对比方法
- CNN
- SAN-2018-Neurocomputing-2018
- Double-layer attention based adversarial network (DA-GAN)-2021-Comput. Ind.
- Weighted adversarial transfer network (WATN)-2021-TIE
- S-SAN models based different AI algorithms
- S-SAN(FCNN)
- S-SAN(DBN)
- S-SAN(LSTM)
- E-SAN
结果
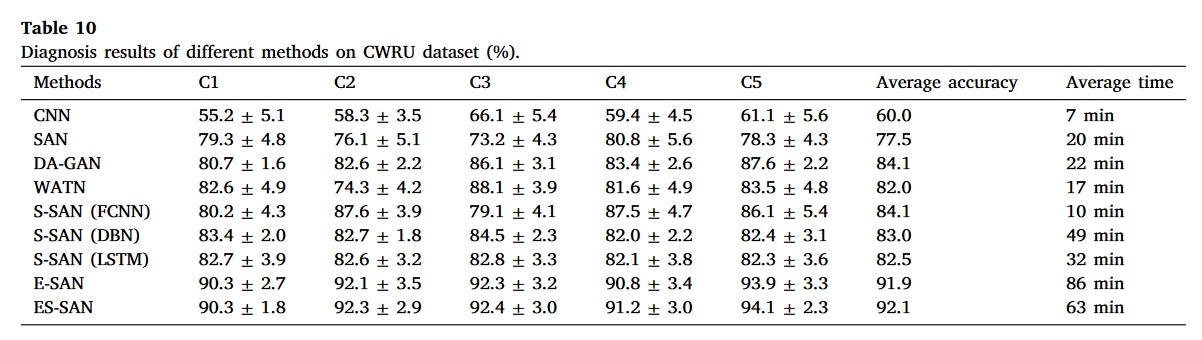
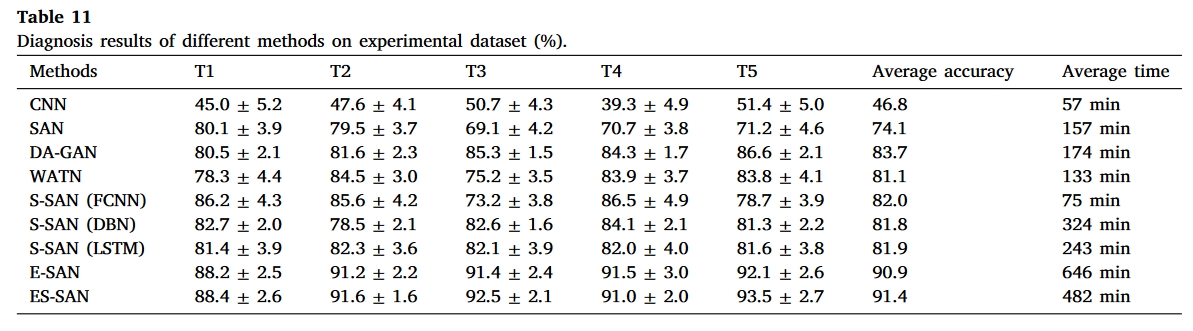
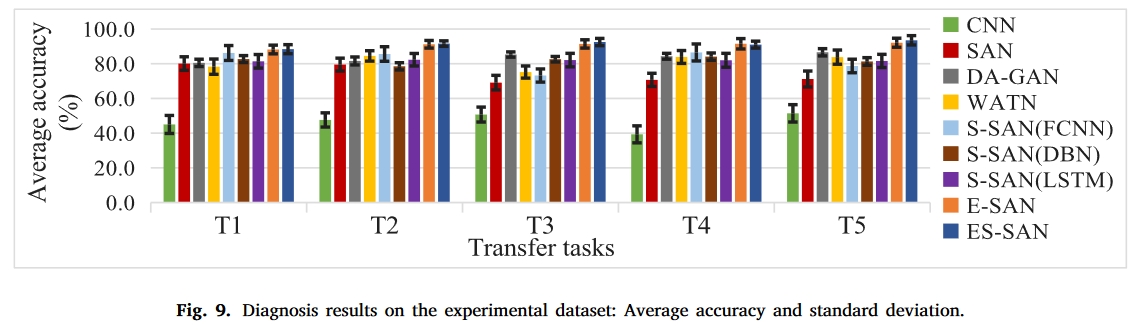
总结
和 A-balanced-and-weighted-alignment-network-for-partial-transfer-fault-diagnosis一样针对源域目标域标签不一致的问题,本文则是在原来SAN(针对Partial TL)的基础上进行改进。而上一文是用两个模块:平衡中心对齐模块和加权对抗对齐模块来解决。不过SAN的是一个很热的网络(发表于2018年的CVPR,引用448)。