期刊: Applied Soft Computing(if:8.7)
引言
故障诊断很重要。由于数据驱动数据处理效率高,在自动化和智能化方面具有优势。其已经取得较好表现。
传统的数据驱动故障诊断研究倾向于从大量标注故障数据中学习分类模型,以获得足够的泛化能力。尽管成功案例不胜枚举,但这些工作大多基于这样一个假设,即训练数据和测试数据遵循相同的分布。然而,在工业任务中,需要诊断的数据一般来自不同的工况,甚至不同类型的机器。
- 因此,在大多数实际诊断场景中,训练集和测试集的数据分布并不一致,这种分布差异很容易导致训练有素的模型泛化能力下降。
- 此外,针对部署场景从头开始重新训练诊断模型甚至是不可能的,因为要收集和注释足够大规模的标注数据实在是太耗费精力了。
因此,近期的研究开始关注一些新兴的研究方向,并试图解决上述问题。然后介绍一系列的深度学习方法。
在机械故障诊断所探索的方法中,迁移学习(即重新利用从现有任务(源领域)中学习到的故障知识来帮助诊断新的但类似的任务(目标领域))在近三年来受到越来越多的关注。迁移学习主要分为两个类别:
- 基于参数转移的微调:通过输入一些带标签的目标数据来微调网络,而网络参数的初始值来自源域中预先训练好的网络。
- 域自适应:主要考虑调整源领域和目标领域之间的特征分布,从而将源数据训练的分类器泛化到目标任务中。由于领域适应方法一般假定目标领域中的大量故障数据是无标记的,因此大多数领域适应方法本质上属于无监督迁移学习流程。
在实际应用中,监测到的机器数据极不平衡,其中大部分属于健康类别。在更极端的情况下,只能获得稀疏数据(每个故障类别只有一个或几个样本)并进行标记。这是一个具有挑战性的问题,其目的是诊断由单个或多个目标样本识别出的目标机器的每个故障类别,以及在源领域学习到的知识。在这样的工程背景下,流行的迁移学习方法,无论是基于参数迁移的微调还是领域适应,仍然有其局限性。本文的创新点如下:
- 利用丰富的源数据和稀疏的目标数据,可以使网络适应目标诊断任务,而不是过度拟合。
- 为了利用类别标签中的鉴别信息,避免在领域适应过程中出现负迁移,设计了多个领域鉴别器,用于学习每个相应故障类别中的领域不变特征。
相关工作
考虑到跨领域故障诊断的实际需求,基于迁移学习的诊断研究不断涌现,通常是通过利用具有丰富监督的现成数据来促进目标模型的微调或适应。由于这项工作是在深度学习框架下设计的,因此只对深度迁移学习方法进行了综述。众所周知,基于参数转移的微调假定只有很少的标注目标数据可用。
在源域和目标域之间存在分布差异的情况下,域适应方法旨在学习域不变的特征表示。最大均值差异(MMD)和对抗训练是深度域适应中两种最有效的方法。
尽管取得了成功,但这些报告的工作一般都要求在适应过程中使用大量具有丰富机器故障特征的目标样本,而忽略了目标域中故障样本稀少的事实。
机器故障状况类内变化极小的稀疏数据无法准确描述目标域的数据分布。
此外,在无监督域适应过程中,数据分布的巨大偏移和不同域的标签空间很容易造成负迁移。图 1 给出了这两种情况的示意图。
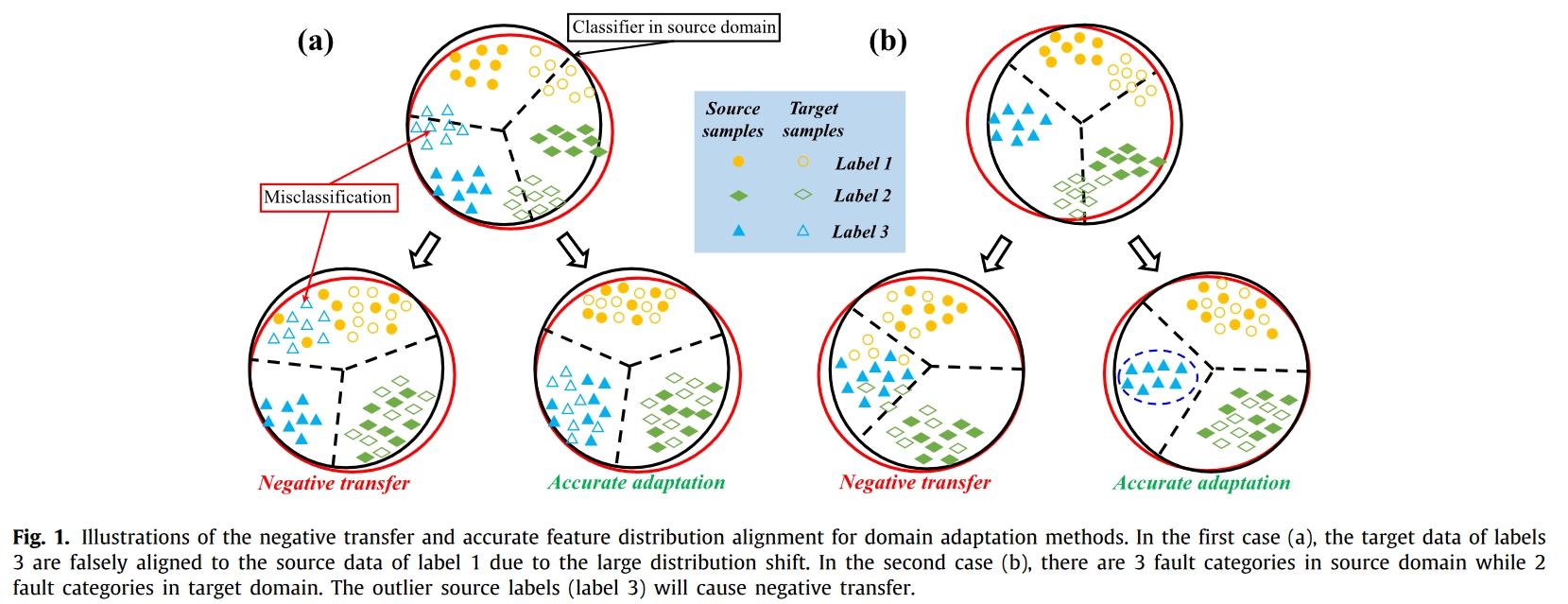
不同领域之间工作条件和机器结构的差异可能会导致数据分布的巨大偏移。因此,如图 1(a) 直观所示,无监督适应过程容易造成不同故障类别的错误对齐。
在大多数现有著作中,源域和目标域通常被假定共享一个相同的标签空间。然而,目标领域中的机器条件是不可见的。源任务和目标任务之间的类别差异很大、特别是在跨机器传输诊断任务中。图 1(b)显示了离群源类别造成的错误配准。由于大多数领域适配方法都是以无监督方式设计的,因此这些工作限制了对稀疏数据类别信息的使用,从而无法找到相似类别并诱导更准确的分布适配。
为了有效地处理稀疏目标数据,本文提出了一种混合方法,即同时用少量监督训练模型和用对抗训练学习领域不变特征,以降低过拟合风险并保持诊断准确性。与之前的研究相比,本研究的主要创新点和贡献如下:
- 大多数传输诊断工作仍然需要少量有标记的目标数据或大量无标记的目标数据。本研究将研究重点转向了稀疏故障数据(每种机器状态只有一个或几个样本)。充分利用稀疏数据的类别信息来提高分类器的判别能力,并从充足的源数据中学习可转移特征。
- 本文提出了一种多重对抗域自适应方法,以考虑机器故障诊断中的两个实际问题,即提高大数据集转移时特征分布自适应的精度,以及考虑部分迁移学习以应对诊断标签空间不匹配的问题。
- 为了证明所提方法的有效性,我们设计了更全面的转移诊断实验,包括不同工况和机器之间的转移任务。特别是在跨机器诊断的情况下,两个轴承数据集的工作条件、机器和故障标签空间都不同,更接近实际的工业应用。
对抗域泛化
最近,许多机器故障诊断研究成功地采用了对抗性域适应[44]。在传统 CNN 的基础上,增加了一个类似于 $G_y$ 的域判别器 $G_d$,从而在 $G_f$ 和 $G_d$ 之间引入了一个 minmax 双人博弈。训练 $G_d $是为了区分源特征或目标特征,而 $G_f$ 则试图学习域不变特征以混淆$G_d$。对抗性域适应的目标函数通常包含源样本的标签损失以及源域和目标域中样本的域损失。其表述为:
$\begin{aligned}\mathcal{L}(\theta_f,\theta_y,\theta_d)&=\frac{1}{N_s}\sum_{x_l\in\mathcal{D}_s}\mathcal{L}_y(\mathcal{G}_y(\mathcal{G}f(x_i)),y_i)\&-\frac{\lambda}{N_s+N_t}\sum{x_i\in\mathcal{D}_s\bigcup\mathcal{D}_t}\mathcal{L}_d(\mathcal{G}_d(\mathcal{G}_f(x_i)),d_i)\end{aligned}$
其中,$θ_f$、$θ_y$、$θ_d$ 分别为 $G_f$、$G_y$ 和 $G_d$ 的参数集合,$d_i$ 表示样本的域标签。
$θ_f$的学习目的是最大化域损失,而$θ_y$的训练目的是最小化域损失。此外,$θ_f$ 和 $θ_y$ 的更新是为了最小化源样本的标签损失。关于 (4) 的优化描述如下:
$\begin{gathered}
\begin{aligned}(\widehat{\theta_f},\widehat{\theta_y})=\arg\min_{\theta_f,\theta_y}\mathcal{L}_0(\theta_f,\theta_y,\widehat{\theta_d})\end{aligned} \
\quad\widehat{\theta_d}=\arg\max\mathcal{L}_0(\widehat{\theta_f},\widehat{\theta_y},\theta_d)
\end{gathered}$
在许多转移诊断案例中,传统对抗网络已被证明能有效地学习领域不变特征,在这些案例中,提供了足够的未标记目标数据,工作条件不同,但各领域的标记空间相同。
详见这篇文章。
提出的方法
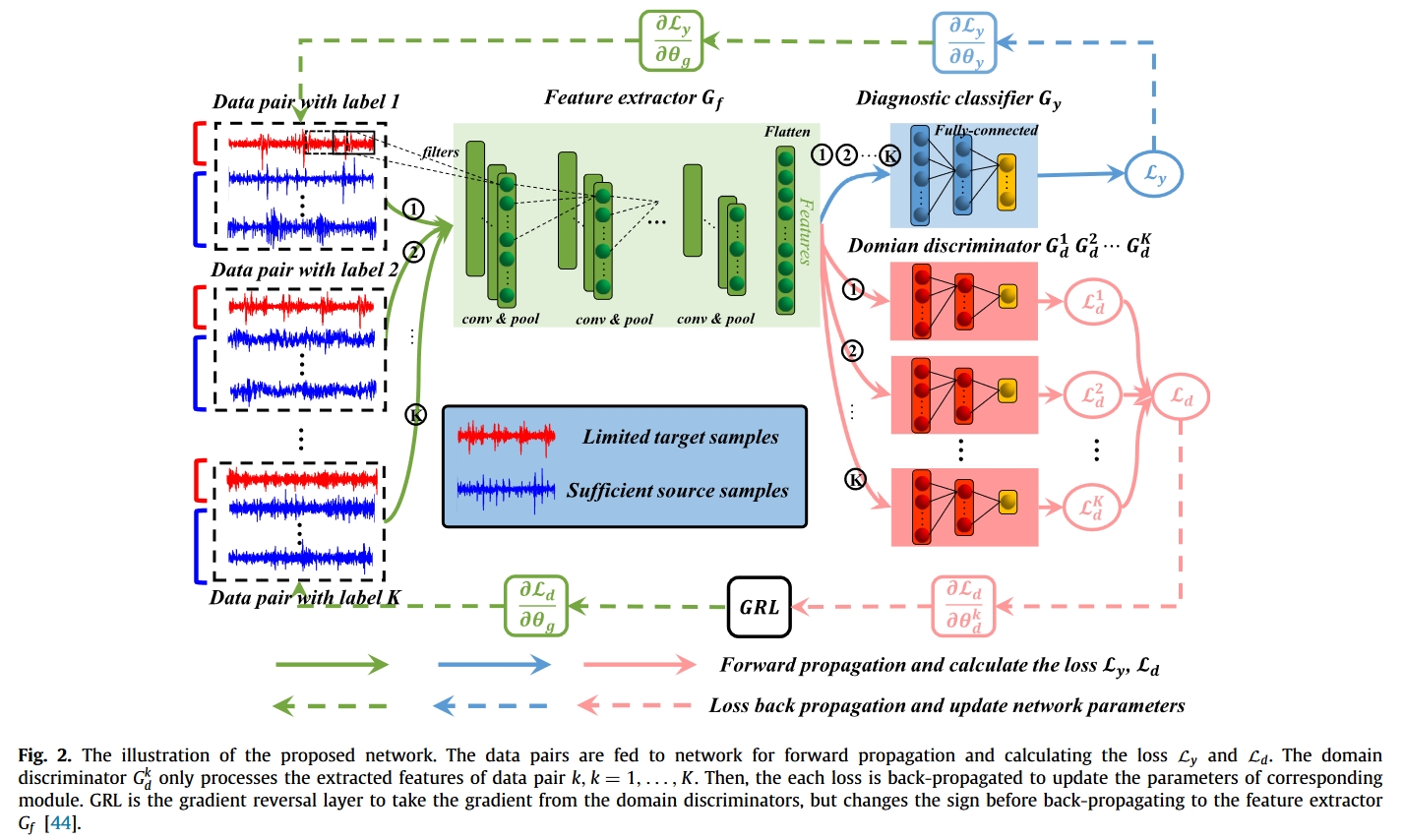
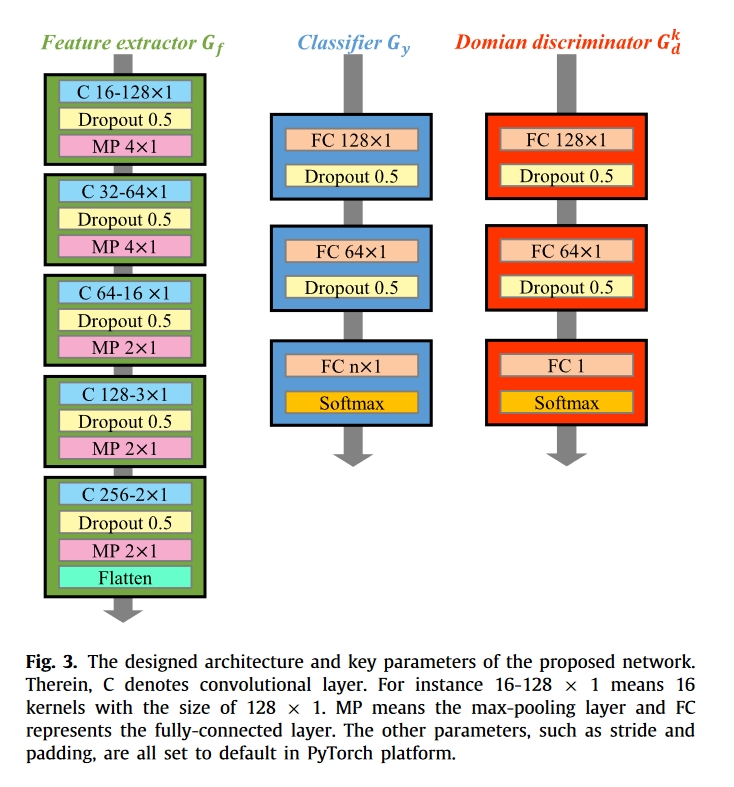
受传统对抗网络的启发,拟议网络由三个主要模块组成:
- 特征提取器 $G_f$
- 诊断分类器 $G_y$
- 多类领域判别器 $G^k_d$(k = 1, 2, ., K .)
海量源样本 ${(x^s_i , y^s_i )}^{N_s}{i=1}$ 和稀疏目标样本 ${(x^t_i , y^t_i )}^{N_t}{i=1}$都被送入特征提取器 $G_f$,以实现抽象特征表示 $f = G_f (x)$。然后,提取的特征被送入分类器 $G_y$ 和多域判别器 $G^k_d,k = 1, 2, ., K$ 分别发送。总的来说,提出的网络主要包括两个部分:监督微调和多重对抗域适应。
$G_y$的损失函数为交叉熵。
为避免在目标监督极少的情况下出现过度拟合,第二阶段通过特征提取器 Gf 和多域判别器$G^k_d,k = 1, 2, ., K$ 的对抗训练在第二阶段进行。
将来自不同领域但相同机器条件的数据配对,本质上是在分布对齐过程中补偿稀疏目标数据所描述的不清晰特征分布。同一机器条件下的域不变特征表示可以通过在数据配对中进行对抗训练来学习。因此,经过源监督和目标监督训练的分类器在目标数据中具有足够的泛化能力。所有 K 个域判别器的域损失定义为:
$\mathcal{L}d=\frac1{N_s+N_t}\sum{k=1}^k\sum_{x_i\in\mathcal{D}_s\bigcup\mathcal{D}_t}\mathcal{L}_d^k(G_d^k(G_f(x_i)),d_i)$
其中,$G^k_d$ 是与标签 k 相关的第 k 个域判别器,$L^k_d$ 表示 $G^k_d$ 的二元交叉熵(BCE)损失,$d_i$ 是域标签(源样本的域标签为 0,目标样本的域标签为 1)。$G^k_d$ 的 BCE 损失 $L^k_d$ 的计算公式为:
$\mathcal{L}_d^k(G_d^k(G_f(x_i)),d_i)=-d_i\log(G_d^k(G_f(x_i)))-(1-d_i)\log(1-G_d^k(G_f(x_i)))$
值得强调的一点是,对于域间诊断标签不匹配的问题,即$ Yt ⊆ Ys$,只针对共享标签建立域判别器,而过滤掉离群的源标签。(这样解决吗?好好好,这么玩是吧)
在训练过程中:
- 对特征提取器 $G_f$ 和分类器 $G_y$ 进行训练,以最小化分类损失 $L_y$,从而准确诊断机器状况。
- 同时,训练 $G_f$ 是为了最大化领域损失 $L_d$,以生成更多共享特征表示,而领域判别器$G^k_d(k = 1, 2, ., K$ 被更新为最小化 $L_d$。

实验
数据集
- Wind turbine fault dataset(自建)
- CWRU
对比方法
- 参数转移 I:将源领域中预先训练好的网络参数转移到目标网络中,目标网络的结构与源网络相同。顶层分类层是根据目标任务定制的。整个网络的参数会根据增强的目标样本进行微调。(Measurement2019)
- 参数转移II:在参数转移I策略的基础上,固定前面卷积层的参数,即θf(也称为冻结层),以减少可训练参数的数量,从而避免过拟合。(IEEE Access2019)
- DTN:通过 MMD 测量最后一个隐藏全连接层的域差异。在损失函数中加入联合分布适应项,以最小化差异。这是一种无监督方法,不使用增强目标数据的标签信息。(ISA T2020)
- DANN:无监督对抗训练用于领域适应。然而,只有一个判别器能区分源数据和增强的目标数据。(TII2020)
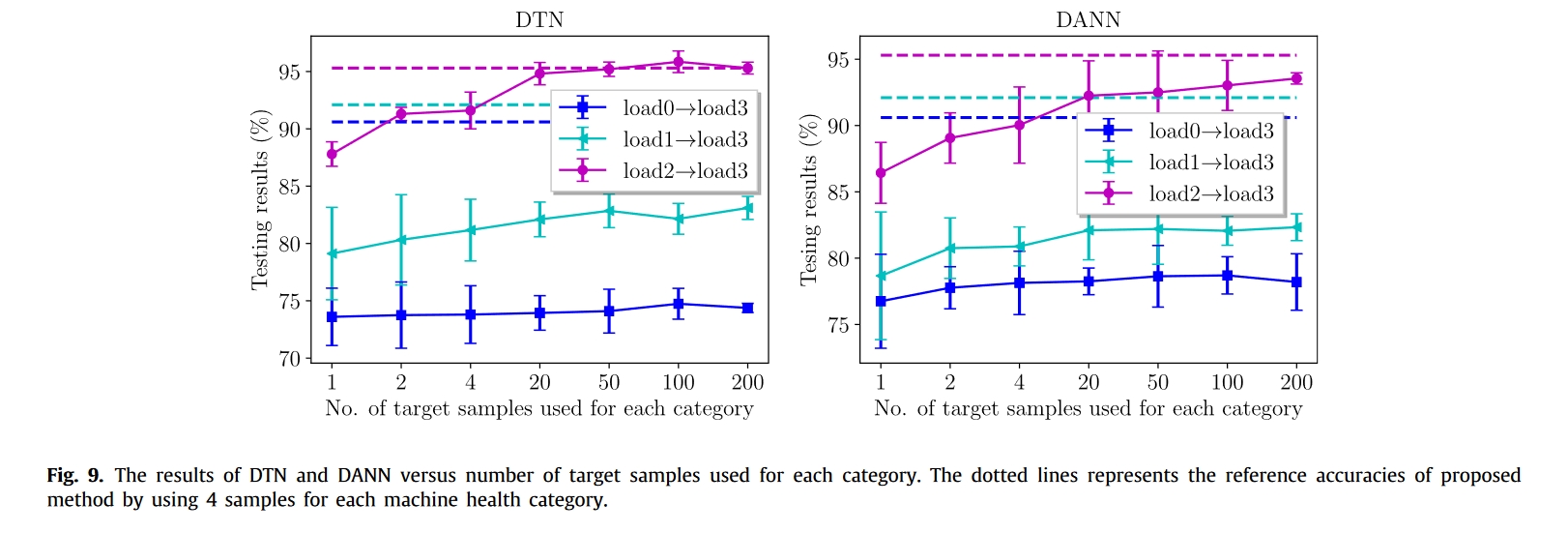
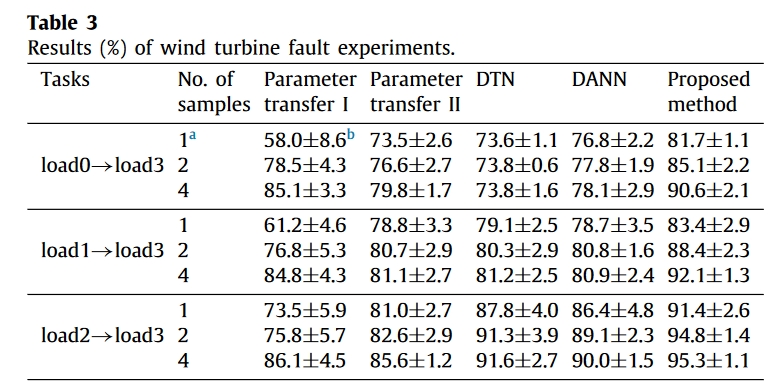
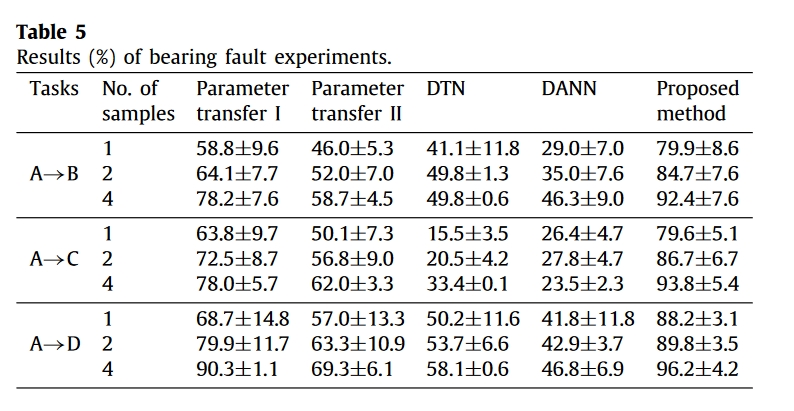
结果
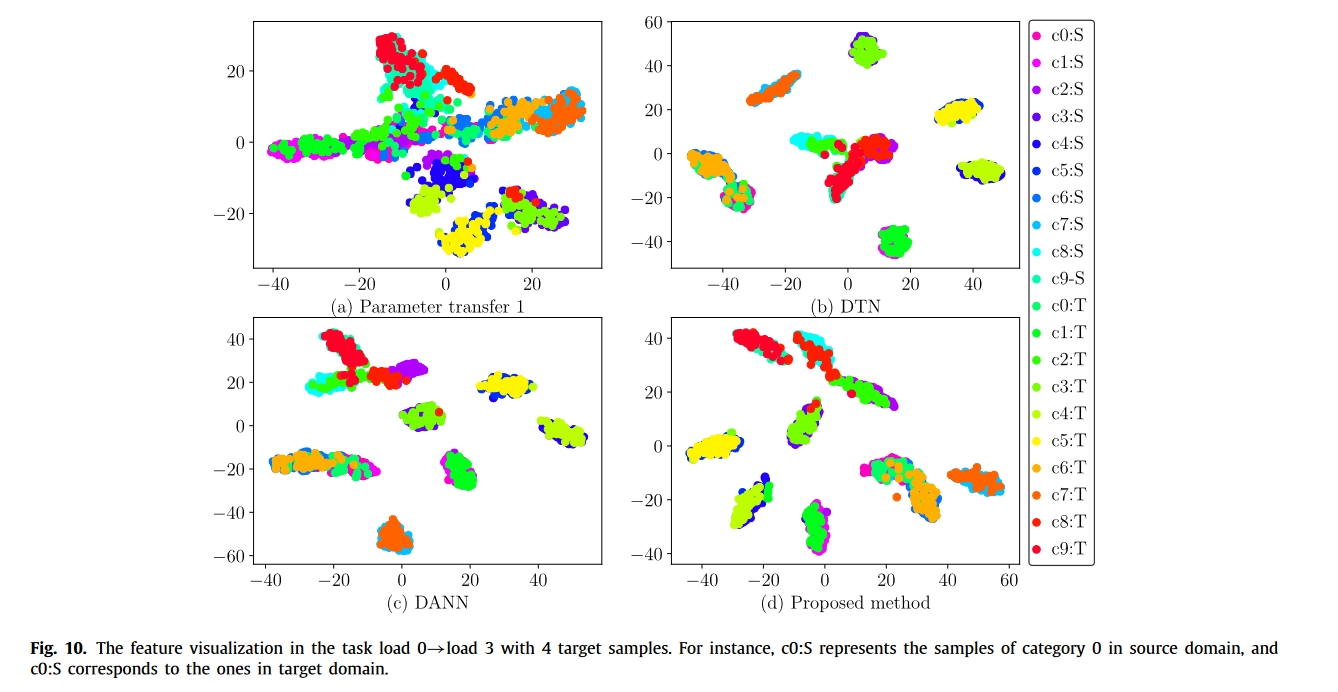
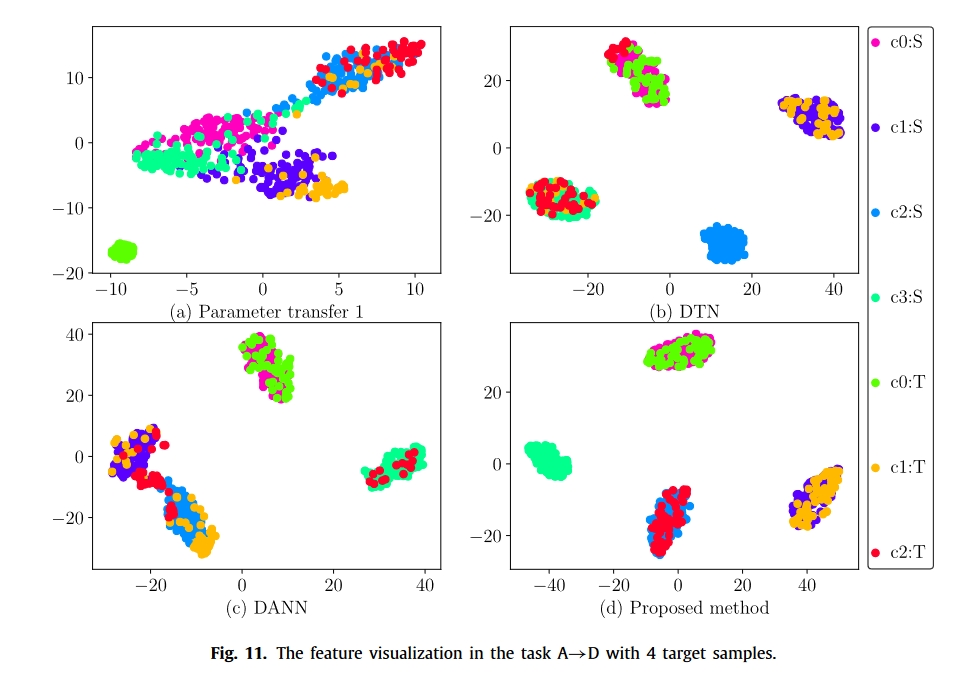
总结
创新点:
- 对抗域泛化应用
- 多鉴别器协同
本文中的稀疏是指样本量少。