期刊: Reliability Engineering & System Safety (IF:8.1)
引言
- 故障诊断对于制造业等至关重要。与传统的故障诊断相比,智能故障诊断(IFD)将机器学习理论应用于机器故障诊断,实现了故障检测和分类过程的自动化。传统的IFD方法包括三个步骤:传感器数据采集、特征提取和故障分类。然而,手动提取特征具有显著的缺点,因为它是任务密集型的,具有不同的故障分类任务和不同的机器工作条件。
- 深度学习方法大大克服了传统IFD方法的不足。然后介绍了一系列的深度学习方法。他们的方法实现了对几个分离和组合故障的高精度、更多的物理可解释性、对噪声环境的高鲁棒性以及实现成本的显著提高。然而,从头开始为IFD训练DL模型将需要大量的训练数据,这些数据包含所有可能的机器故障条件。这在实际应用中是一个重大挑战,因为仅针对某些故障条件的测量数据可能远远不够。
- 为了解决训练数据有限的问题,引入了迁移学习(TL),它通过微调在其他任务中预先训练的DL模型,在获得令人满意的深度架构方面表现出了非凡的能力。然而,TL所基于的来自完全不同应用程序的预训练模型可能没有学习到最具代表性的特征。参数转移学习策略实现了更稳健的故障诊断结果,其中使用目标域中的少量样本对基于从原始系统收集的数据训练的预训练模型进行微调。然而,缺乏源域中所有故障条件的测量数据仍然是使用参数迁移学习的主要瓶颈。
- 介绍了数字孪生的概念。物理设备的高保真数字模型可以生成接近真实资产的系统性能模拟数据。通过生成不可用故障条件的模拟数据,DT 为 IFD 提供了新的机遇。最近,一些研究人员对故障诊断和预测性维护中的 DT 进行了研究。该模型生成了用于故障诊断目的的各种典型故障的误差残差。然而,还没有开发出一种系统的方法来提高使用DT的机器故障诊断性能,以克服测量数据有限的实际问题。
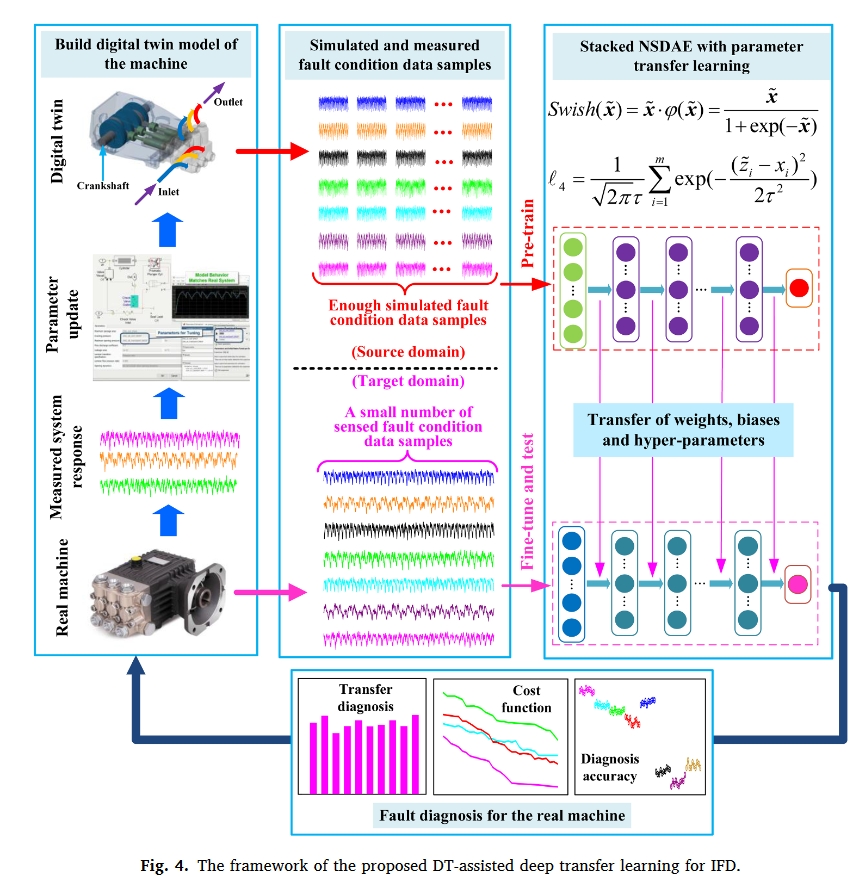
- 本文为机器IFD开发了一种新的DT辅助深度迁移学习框架。该机器的DT模型提供了可能的故障条件的模拟数据,从而克服了某些故障条件下数据不可用的问题。通过自适应更新DT模型来解决系统特性变化的挑战。基于稀疏去噪自动编码器的改进深度迁移学习方法可以充分利用源域数据和目标域中极少量数据的训练模型。通过对三缸泵故障诊断的实例研究,对所提出的IFD的性能进行了评估。本文的主要贡献如下:
- 提出了一种利用DT和深度迁移学习进行机器故障诊断的新框架,解决了在不同工作条件或系统特性变化的情况下,机器故障状态测量数据有限或不可用的问题。机器的DT被构建并不断更新,以生成与实际设备接近的可能故障条件。DT模型产生的故障条件数据在源域中构造用于迁移学习的训练数据。
- 开发了一个NSDAE来构建深层结构。使用了Swish激活函数,与常用的整流线性单元(ReLU)或其他激活函数相比,它获得了优越的结果。
- 为了训练NSDA,在代价函数中引入了最大相关度(Max corr)。与均方误差(MSE)相比,Max corr在测量两个复杂信号的局部相似性方面更有效。
- 在目标域中只有一个样本的情况下,该方法通过将预先训练的源域NSDAE的模型参数成功转移到目标域NSDAE来实现一次性学习,解决了在目标域使用有限数据进行有效训练的困难。
去噪自编码器
尽管DBN具有为输入数据提供联合概率分布的能力,但这很难在IFD任务中分析实值振动数据。由于具有强大的监督特征学习能力,CNN被认为是IFD领域应用最广泛的深度学习模型,但CNN结构复杂,计算成本高。作为一种完全无监督的学习模型,SAE比DBN和CNN更容易、更有效地训练,并衍生出许多改进形式,如稀疏自动编码器和去噪自动编码器。稀疏去噪自动编码器(SDAE)充分结合了稀疏自动编码器和去噪自动编码的优点,可以有效地从噪声输入样本中学习稀疏特征表示。下图显示了SDAE的模型体系结构。
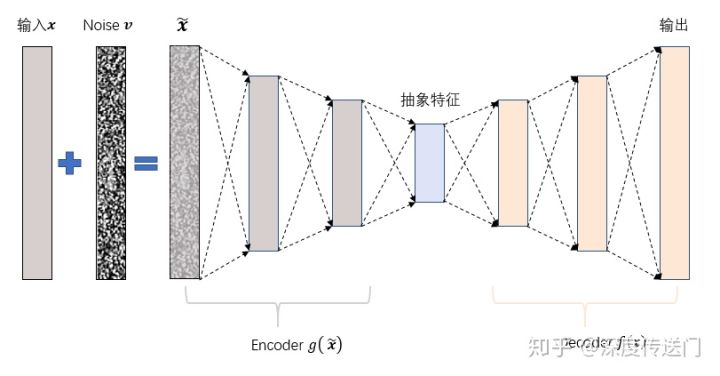
提出的方法
基于DT技术和深度迁移学习模型,本文提出了一种新的机器智能故障诊断框架。所提出的深度迁移学习模型主要包括三个部分:NSDAE构建、堆叠NSDAE的参数迁移和DT辅助的IFD深度迁移学习。
构建NSDAE
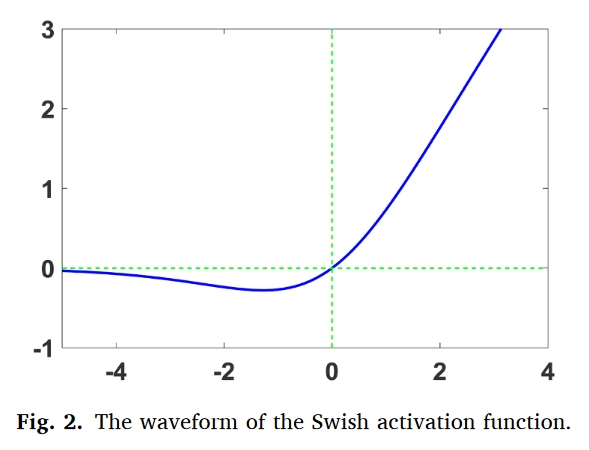
Swish激活函数
$$Swish(\widetilde{x})=\frac{\widetilde{x}}{1+\exp(-\widetilde{x})}$$
Maximum Correntropy (Max-corr)
为了有效地测量真实输入样本和重建样本之间的局部相似性,这里使用了Max corr,它显示出比MSE更好的性能。
Maximum Correntropy是一种基于核空间的局部相似度度量,它可以用来处理非高斯的噪声和异常值。Maximum Correntropy Criterion (MCC)是一种优化准则,它要求在固定的核宽度下,选择模型参数使得输出和期望响应之间的Correntropy最大。MCC可以应用于许多信号处理和机器学习的领域,例如回归、滤波、聚类等。MCC的优点是它不需要假设噪声的分布,而且对于重尾噪声和离群点有很好的鲁棒性。MCC的缺点是它的计算复杂度较高,而且核宽度的选择对于结果有很大的影响。
$SSE=\sum_{i=1}^{m}w_i(y_i-\hat{y_i })^2$
$MSE=\frac{SSE}{n}=\frac{1}{n}\sum_{i=1}^{m}w_i(y_i-\hat{y_i })^2$
$$MCC=\frac1{\sqrt{2\pi}\tau}\sum_{i=1}^m\exp\left(-\frac{\left(\widetilde{z}_i-x_i\right)^2}{2\tau^2}\right)$$
$\tau$是核宽度可调参数。
Parameter transfer of the stacked NSDAE
参数迁移学习是一种有效的策略,可以大大提高已经预训练的堆叠NSDAE的训练效率。通过参数迁移学习,使用来自一个域(源域)的数据样本训练的堆叠NSDAE可以很好地分析来自具有不同分布的另一个域的数据样本(目标域)。
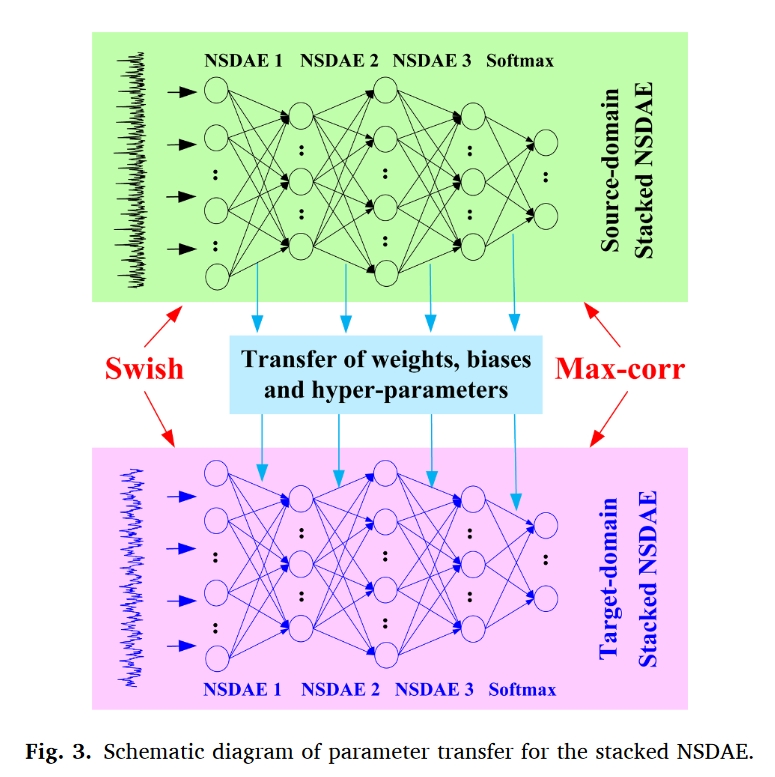
迁移学习后的模型可以用于有效的机器故障诊断。所提出的方法的主要步骤是:
- 创建实际机器的模拟模型(例如,在MATLAB Simulink和Simscape中)。
- 收集系统响应的测量数据,并通过最小化模拟模型和测量数据之间的系统响应差异来更新模拟模型。
- 建立DT模型,模拟机器所有感兴趣的故障。将不同机器条件下生成的模拟数据视为源域数据。
- 构造具有Swish激活功能和MCC的堆叠NSDAE。
- 来自源域的训练和测试样本用于获得具有高且稳健诊断精度的预训练堆叠NSDAE。
- 为了在目标域中实现机器故障诊断(在变化的工作条件或变化的系统特性下),仅通过来自目标域的一个训练样本对预训练的堆叠NSDAE进行微调,以进一步调整模型权重。
- 使用来自目标域的测试样本来检查所提出方法的有效性。最后堆叠的NSDAE可以部署在正在运行的机器的故障诊断中。
实验
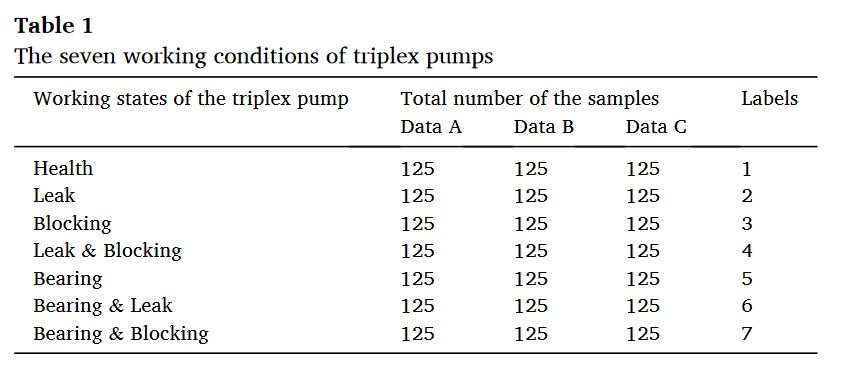
数据集
如图5所示,使用[26]中的Matlab中的Simscape创建了实际三缸泵的仿真模型。在这里,我们修改了系统参数,包括上压力和下压力,在这个水平上,给出口供水的三个止回阀将打开和关闭,以模拟变化的系统特性,例如,运输流体的温度和性质的变化。然后生成具有修改参数的模型的系统响应,并将其用作转移的实际资产的测量数据,以优化仿真模型。在本研究中,DT模型的更新是通过Simulink设计优化实现的,并自动调整模型参数。采用顺序四次规划的梯度下降法来最小化出口压力模拟曲线和测量曲线之间的差异。
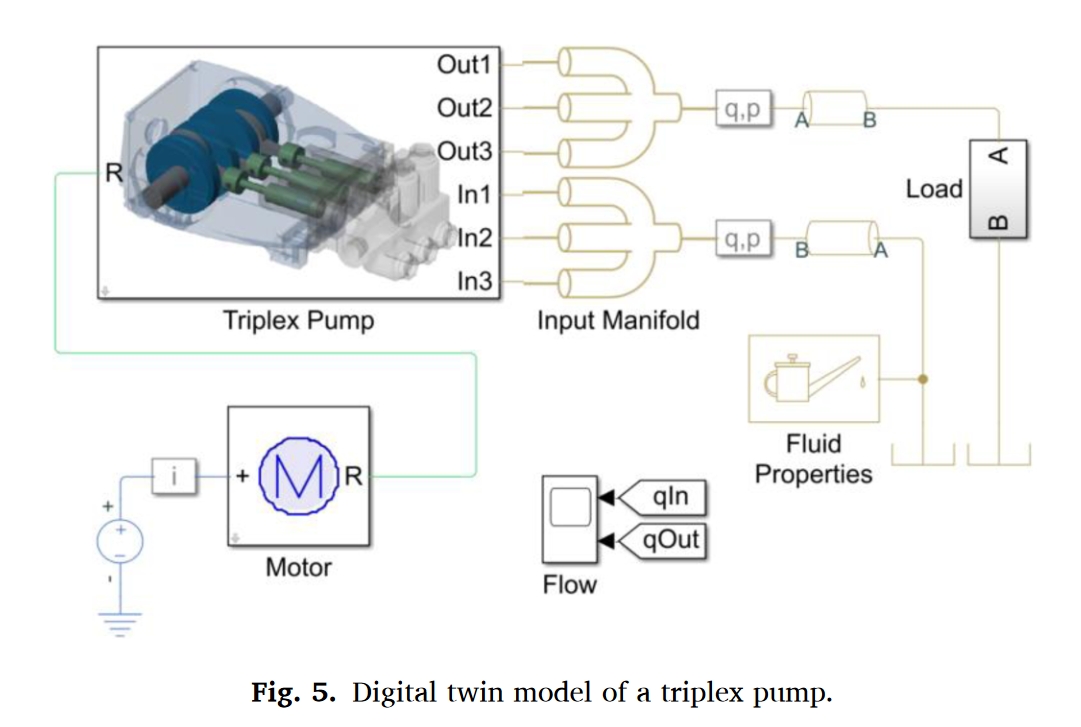
实验结果
Task1
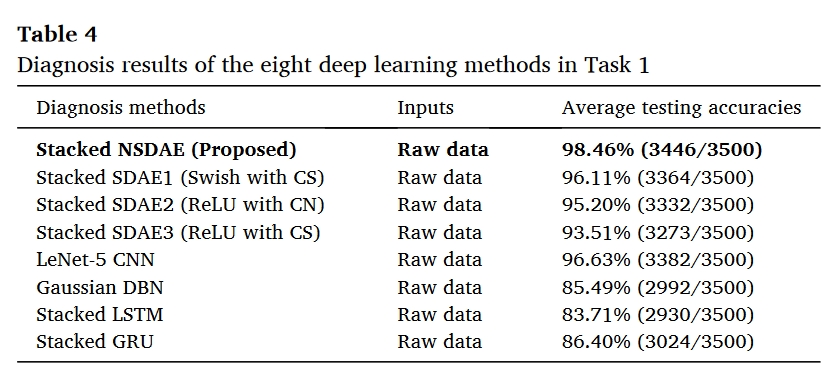
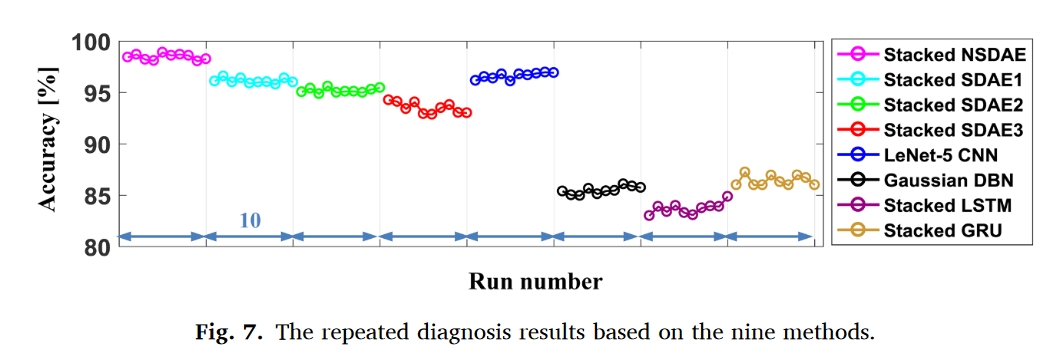
任务1的重点是使用原始输出流数据测试已开发的堆叠式NSDAE的诊断性能。
Task2
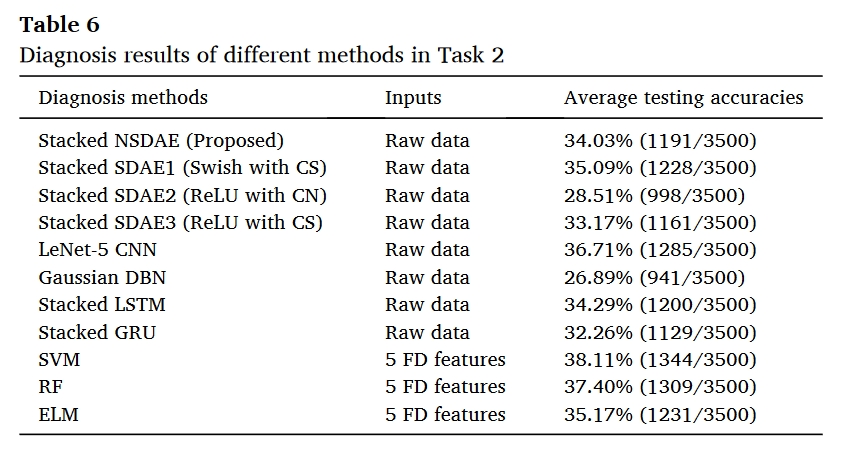
任务2用于测试堆叠NSDAE和其他深度学习方法在应用于实际系统时(通过模拟)的诊断性能是否会降低。
Task3
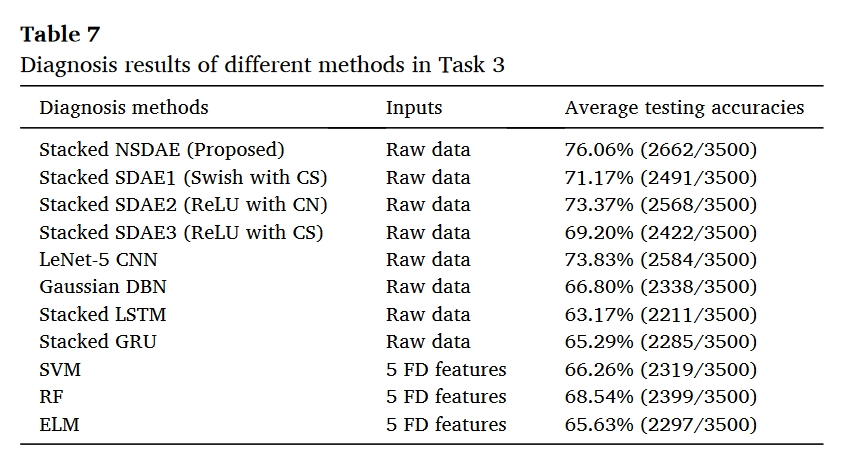
任务3旨在评估DT模型的数据集C(源域)在DT模型优化后与更改模型的数据集中B(目标域)具有相似的分布。
总结
对去噪自编码器换了激活函数和量化指标。主要是结合了Matlab的物理模拟系统生成模拟信号辅助故障诊断。