期刊: IEEE Transactions on Cybernetics(IF:11.8)
引言
机械滚动部件很重要。现有的诊断方法包含3类:
- 基于模型的方法:基于模型的方法侧重于建立机械系统的动态模型,该模型可以将机械知识和控制理论技术相结合,以自动方式处理故障。
- 基于信号处理的方法:基于信号处理的技术试图通过时域、频域和时频技术来挖掘关键部件的故障信息,以揭示缺陷特征。
- 基于数据驱动:而数据驱动的方法利用人工智能模型来构建测量数据和最终预测精度之间的关系
深度学习方法引起了很大的关注。然而,有监督的DL故障诊断方法通常遵循隐含的假设,即训练和测试数据是在相同的数据分布下从相同的机器收集的。在工业应用中,这种假设通常很难满足,因为不同任务的机械操作条件通常不同。因此,训练数据和测试数据的特征空间将呈现显著的分布差异,导致现有监督DL诊断方法的诊断性能下降。
介绍域自适应及其相关方法。
DA诊断技术的研究在减少各种诊断任务中的跨域分布差异方面取得了实质性进展。然而,如图1所示,传统的基于DA的故障诊断假设源域和目标域必须保持相同的标签空间。因此,它们只能识别源域中包含的故障类,而无法识别目标域中的未知类型。在工业应用中,在某些运行条件下,收集包含一些已知故障的历史数据可能很容易。然而,由于操作条件的变化和恶劣的工作环境,训练数据中没有观察到的新故障可能是随机发生的。这是指开集故障诊断,它表示从不同的操作条件中获取训练数据(源域)和测试数据(目标域)。
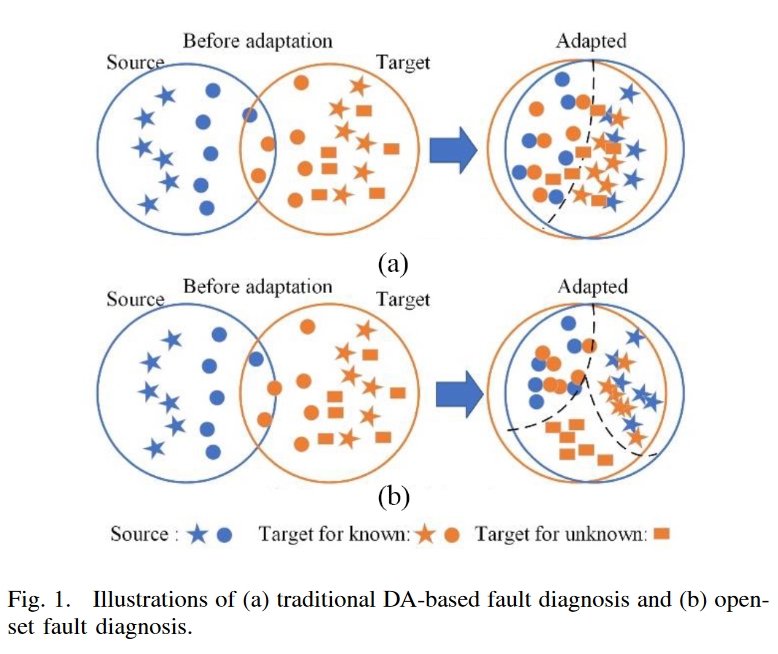
目前,这一开集(open-set)故障诊断问题在诊断研究工作中受到的关注较少。然后介绍了一些相关的工作。
然而,目前的研究主要集中在单一源代码的开放集DA诊断问题上,并没有充分利用多源故障类别信息。
为了解决上述问题并提高诊断性能,开发了一种用于机械开集故障诊断的多源加权深度转移网络(MWDTN)。构造了具有自适应加权学习策略的深度开放集对抗性网络,该网络能够充分利用底层标签信息,并自适应地生成边界来识别已知和未知类别。所提出方法的主要贡献如下:
- 提出了一种新的基于MWDTN的开放集DA方案用于机械故障诊断。所提出的方法专注于一个更具挑战性的诊断问题,即故障类别的标记样本分布在具有不同标签空间的多个互补源域上。因此,它旨在将知识从多源数据转移到目标领域的诊断任务中,这扩展了开放集诊断方法的工业应用,其中不存在来自单个源领域的完全故障类别。
- 构造了一个自适应加权学习模块,该模块允许充分利用来自已知和未知类别的潜在标签信息。同时,构造了具有额外未知类输出的领域分类器。它可以进行自适应加权训练,将未知目标样本与已知样本区分开来,通过建立经验硬阈值而不是自适应阈值来拒绝未知类别,克服了现有诊断方法的缺点。
- 建立了不同的开放集DA诊断任务,并采用了一系列先进的基于DA的诊断方法进行比较。最终的故障诊断精度和可视化结果表明,该方法不仅可以有效地缓解共享源域和目标域之间的数据分布差异,减少新出现样本的负面影响,而且明显优于其他现有的比较方法。
方法
在本节中,描述了所提出的基于MWDTN的开集DA智能诊断方法。
开集DA诊断问题的关键挑战在于缺乏将目标样本分为已知或未知类别的概率度量。
其基本思想是训练一个二进制分类器,通过假设所有未知数据属于一个类来分离已知和未知类别的目标数据。然而,当源域和目标域不仅来自不同的数据分布,而且未知数据包含多个未知类别时,这种方法的诊断性能是值得怀疑的。
因此,首先开发了一个深度开放集对抗性网络来生成属于已知或未知类别的目标数据的度量。
然后,为了充分利用目标数据的潜在领域类别信息,构建并集成了加权学习模块,以推动跨领域的正向迁移。所
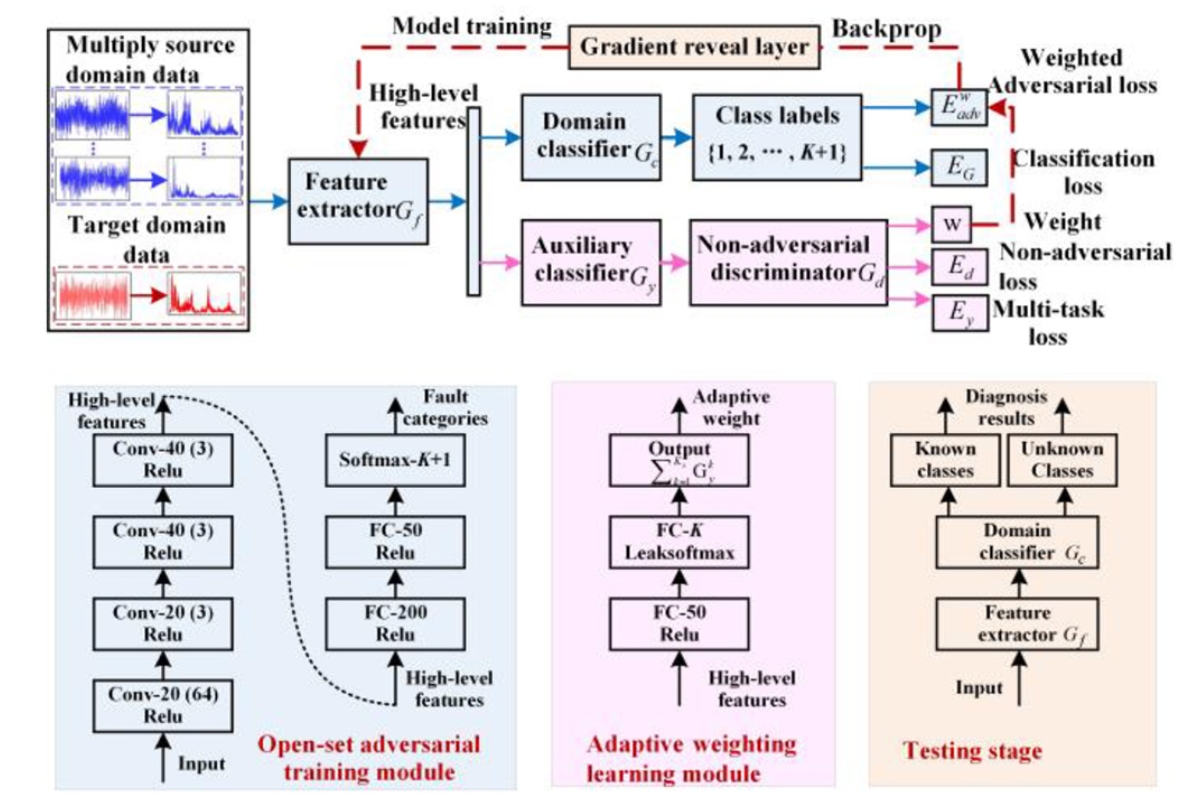
提出的方法如图所示。主要由三部分组成:
1)数据预处理;
2) 开放集对抗性训练模块;
3)基于辅助分类器的自适应加权学习模块。
数据据预处理
在将数据输入所构建的网络之前,对从旋转机械收集的原始时间序列信号进行预处理。
首先将不同故障类型之间的振动信号划分为相等的长度,以获得训练样本和测试样本。
然后,通过快速傅立叶变换将其进一步转换为频谱,因为与原始振动数据相比,频谱可以很好地揭示机械信号的故障特征。
最后,用z分数对频谱进行归一化,这有助于加快神经网络的覆盖率。
开集(open-set)对抗训练模块
开集对抗性训练模块试图通过DA方法的对抗性训练提取域不变性特征来减轻源域和目标域之间的分布差异。
如上图所示,Open-Set Adversarial Training Module主要包含两个部分:特征提取器$G_f$和域分类器$G_c$。
特征提取器$G_f$包括多重卷积、批量归一化和池化层,其同时从源域$D_s$和目标域$D_t$获取旋转机械的振动频谱。构造域分类器$G_c$以获得未知类的p(y=K+1|x)=t,其中t∈{0,1}。然后,对特征提取器$G_f$进行优化,以通过最大化分类器误差来欺骗域分类器$G_c$。这意味着特征提取器$G_f$可以被训练为通过将目标数据与已知或未知类别对准来减小或增加未知类别概率p(y=K+1|x)。t的值通常设置为0.5,以在已知类和未知类之间创建令人满意的边界。
基于辅助分类器的自适应加权学习模块
开集对抗性训练模块仅依赖于$G_c$的伪决策来识别已知和未知类别。但是硬边界阈值t=0.5和缺乏这样的领域知识将给出目标样本的不确定预测。因此,在训练阶段,网络会很容易转移表现。例如,来自目标数据的未知类别将与已知类别匹配不佳。
为了增强正迁移并提高分类性能,通过利用目标样本的底层类先验知识,构建了由辅助分类器$G_y$和非对抗鉴别器$G_d$组成的基于辅助分类器的自适应加权学习模块。
辅助分类器$G_y$由完全连接层和输出层组成。构建它是为了判断未标记的目标样本和标记的源域样本之间的相似性,其中leakysoftmax函数用于预测源域的类别标签,而总概率小于1。这样,辅助分类器$G_y$可以将高级特征转换为K维类概率。Leaky-Softmax的最终输出定义为:
$$G_y(o)=\frac{\exp^2(o)}{K_s+\sum_{k=1}^{K_s}\exp(o_k)}$$
其中o是输出向量。对于源样本,LeakySoftmax输出的元素和接近于1,对于目标样本,则接近于0。由于$G_y$仅基于源样本进行优化,因此可以认为$G_y$对源数据具有较大的概率置信度输出,而对目标数据具有较小的值或不确定性预测。
因此,非对抗鉴别器$G_d$的输出层表示为式(9):
$$G_d(G_f(x))=\sum_{k=1}^KG_y^k(G_f(x))$$
其中$G_d(G_f(x))$表示属于第$k$个已知类别的样本的概率。$G_d(G_f(x))$的值越高,样本存在于跨域共享标签空间中的可能性就越高。相反,值越小,样本来自目标域的置信度越高,这将被视为新出现的故障类型。因此,$G_d(G_f(x))$是否被用作归属于共享标签空间的目标数据的似然指示符。因此,可以定义权重来测量目标数据与源域的相似性:
$$\mathrm{w}\big(\mathrm{x}_i^t\big)=G_d\big(G_f\big(x_i^t\big)\big)$$
可以看出,当$\mathrm{w}(\mathrm{x}_t^i)$获得大概率值时,这意味着目标样本被分配到共享类别的几率很高,而出现故障类别的几率较低。非对抗鉴别器的输出值提供了样本来自源域或目标域分布的概率。
最后,考虑$K_s$上具有多任务损失的$G_f$和$G_y$,具有一个剩余二进制熵的网络分类损失函数表示为
$$\begin{aligned}
E_{G_{\mathrm{y}}}& =-\frac1{n_s}\sum_{i=1}^{n_s}\sum_{k=1}^Ky_{i,k}^s\log\left(G_y^k(G_f(x_i^s))\right) \
&+\frac1{n_s}\sum_{i=1}^{n_s}\sum_{k=1}^Ky_{i,k}^s(1-y_{i,k}^s)\log\Bigl(1-G_y^k\bigl(G_f\bigl(x_i^s\bigr)\bigr)\Bigr)
\end{aligned}$$
其中$y^s_{i,k}$指示类别k是否是源样本$x^s_i$的基本事实类标签。辅助非对抗鉴别器$G_d(G_f(x_i))$的损失可以如下式(12)获得:
$$\begin{aligned}E_{G_d}&=-\frac1{n_s}\sum_{i=1}^{n_s}\log(G_d(G_f(x_i^s)))\&-\frac1{n_t}\sum_{j=1}^{n_t}\log\left(1-G_d\Big(G_f\Big(x_j^t\Big)\Big)\right).\end{aligned}$$
从(9)和(12)中可以发现,非对抗鉴别器$G_d$的输出依赖于特征提取器$G_f$和辅助分类器$G_y$的输出。这确保了$G_d$利用判别性已知和未知类别标签信息进行优化,弥合了已知和未知分类之间的差距,以更好地测量不同样本的重要性。
实验
数据集
- Gearbox Dataset(自建)
- Rolling Element Bearing Dataset(自建)
对比方法
- DACNN-KBS2019
- DAN-IEEE Access2018
- MLDAN-Signal Procession2021
- Maximum Classifier Discrepancy Method-CVPR2018
- DATLN-IEEE Sensor Journal
结果
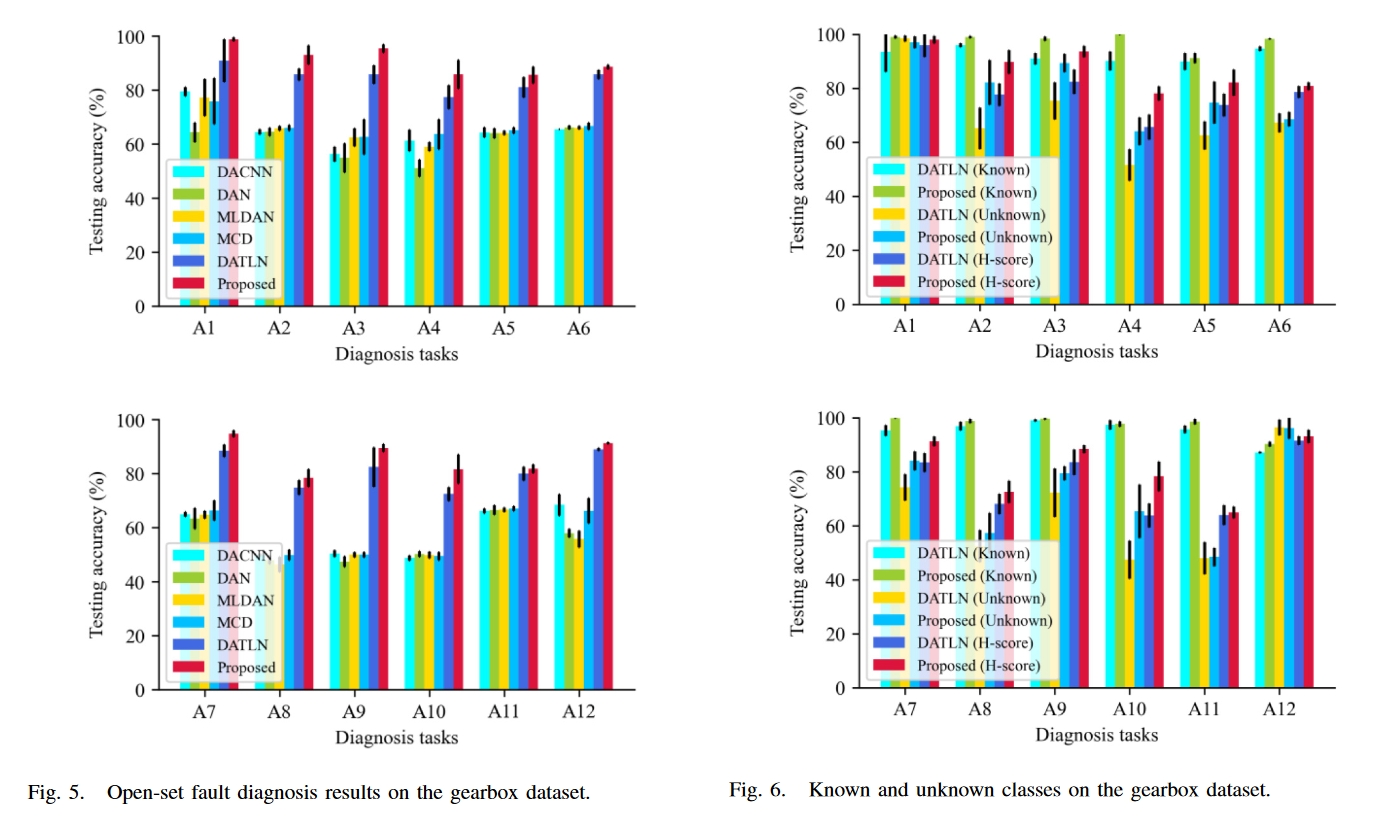
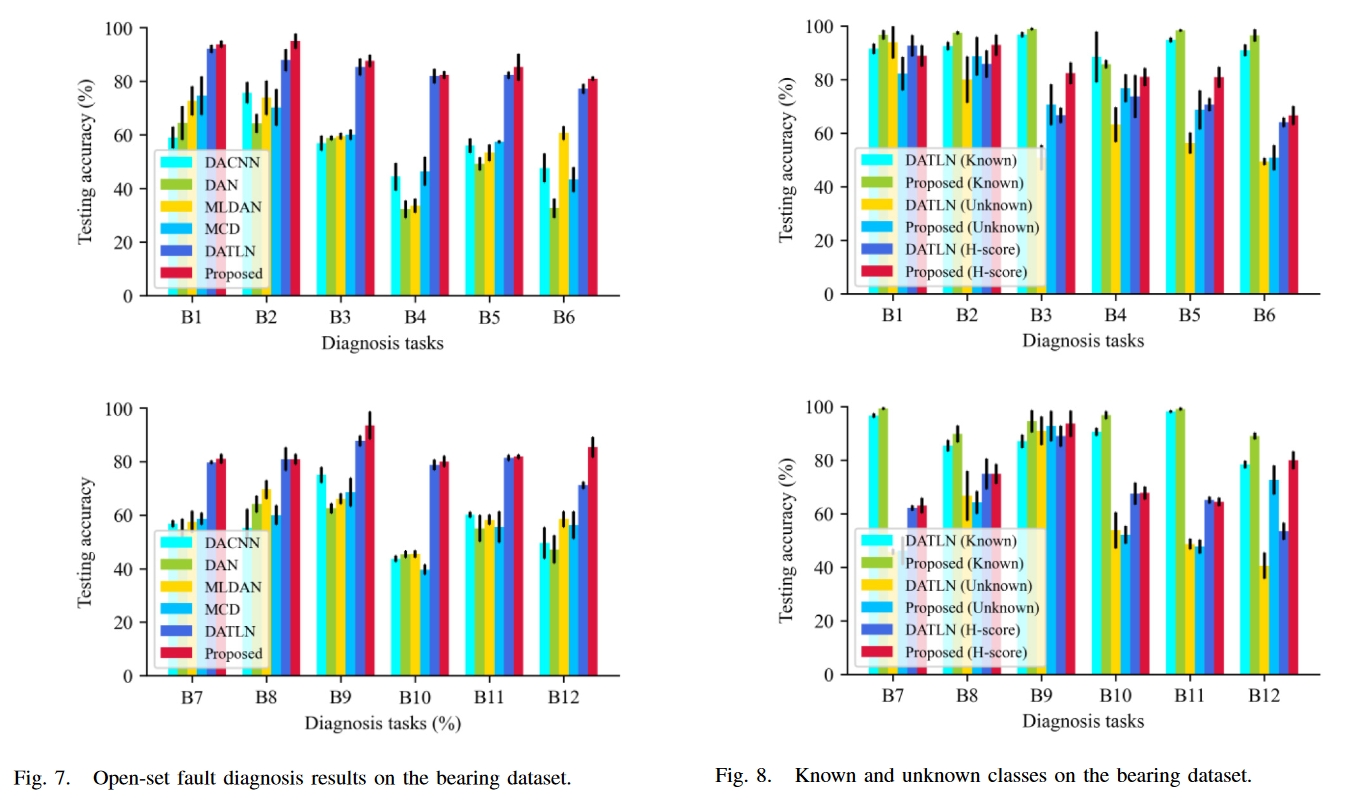
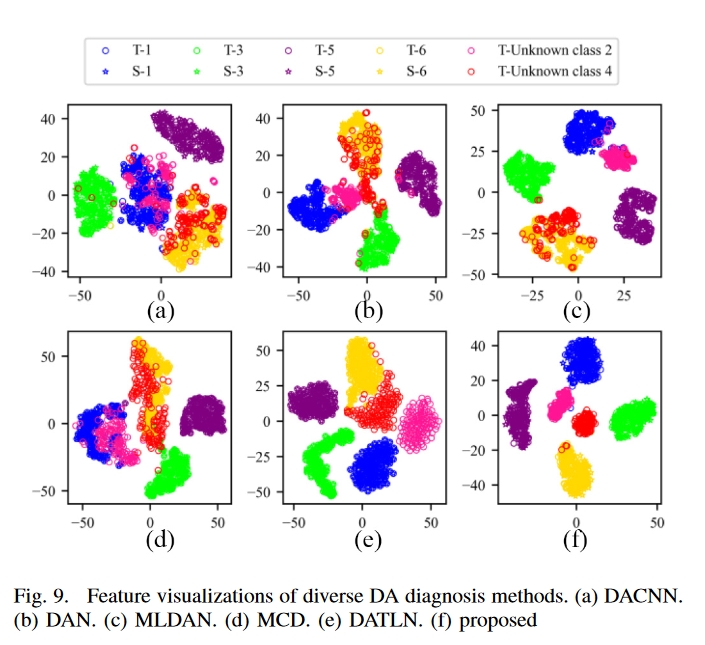
总结
了解迁移学习域泛化中,源域和目标域类别不一样这样一个方向(open-set问题)。以及本文用辅助分类器对应的GAN 网络来解决这个问题。