期刊: Reliability Engineering & System Safety (IF:8.1)
引言
- 机械设备在航空航天、石化、风电、交通运输、医疗设备等领域发挥着至关重要的作用,故障直接影响上述机械设备的正常运行。因此,监测运行状态并识别发生的故障对于提高机械设备的正常运行具有重要意义。随着人工智能技术的发展和海量监测数据的积累,智能诊断方法已成为机械故障诊断的“主力军”。
- 现实工业环境中数据往往不够,因此聚合多用户的数据是一种解决方法。但是由于工业竞争、利益相关和因此安全等原因,不能直接联合。
- 介绍了联邦学习可以解决这个问题,以及其优点。
- 但是多用户的数据往往并不是同分布的。并且由于多用户的场景,直接使用域泛化统一分布并不能直接用。
- 因此,提出了一种新的具有数据隐私的联合多源域自适应方法用于机械故障诊断。与现有的联邦域自适应方法相比,该方法不仅关注将所有客户端数据(源域)迁移到中央服务器数据(目标域),而且考虑了不同源域之间的分布差异,可以显著减少联邦学习中的负迁移现象。本文的创新点在于:
- 针对具有数据隐私的机械故障诊断问题,提出了一种联合多源域自适应方法。
- 引入了联合特征对齐思想,以最小化不同源域和目标域之间的特征分布差异。
- 提出了联邦域自适应中的两种负迁移,并引入了特征鉴别器来减少特征对齐过程中的负迁移现象。
- 设计了一种联合投票方案,以实现目标任务的优越结果。
相关工作
联邦系统本质上由一个中央服务器和N个客户端组成,其中中央服务器代表未知的目标域,客户端N代表第N个源域。
出于隐私原因,数据不能在不同的客户端之间以及客户端和中央服务器之间共享。
因此,联邦系统采用不同客户端共享的局部模型的直接聚合来获得全局模型,从而确保了训练数据的隐私性。
联邦系统的培训步骤如下所示。
- 中央服务器向所有客户端发送初始化的全局模型$B_0$。
- 客户端n使用来自源域$D_s^n$的$K^{(n)}$个样本执行本地模型更新,并将模型更新$C^{(n)}_{t+1}-B_t$返回到中央服务器。
- 中央服务器基于FedAvg聚合所有本地模型更新,完成全局模型更新并再次发送给所有客户端。
中央服务器在训练步骤t的聚合结果描述为:
$$B_{t+1}=B_t+\sum_{n\in N}\frac{K^{(n)}}{\sum_{n\in N}K^{(n)}}\left(C_{t+1}^{(n)}-B_t\right)$$
本研究的目的是使用N个标记的源域${D_s^n}^N_{n=1}$和未标记的目标域Dt,以训练能够准确识别未标记目标域的联合多源域自适应模型。与传统的领域自适应研究不同,本研究关注的是真实行业场景中的数据隐私,即数据无法在客户端之间共享,中央服务器无法查看每个用户的数据。
负迁移(negative transfer)
负迁移是迁移学习任务中的一个常见问题,即源领域的知识导致目标领域的识别结果越来越差。
因此,本文研究了联邦转移任务中的负转移情况,并直观地展示了所提出的方法解决负转移问题的能力。
联邦转移任务包含两种形式的负转移,一种是常规转移任务中广泛的负转移称为个体负转移,另一种是联邦转移任务中唯一的负转移也称为组负转移。
方法
本研究的目的是确保所提出的框架对具有数据隐私的目标任务进行准确诊断,同时提高全局模型的通用性,并减少所提出框架的负迁移现象。
本文方法结构图:
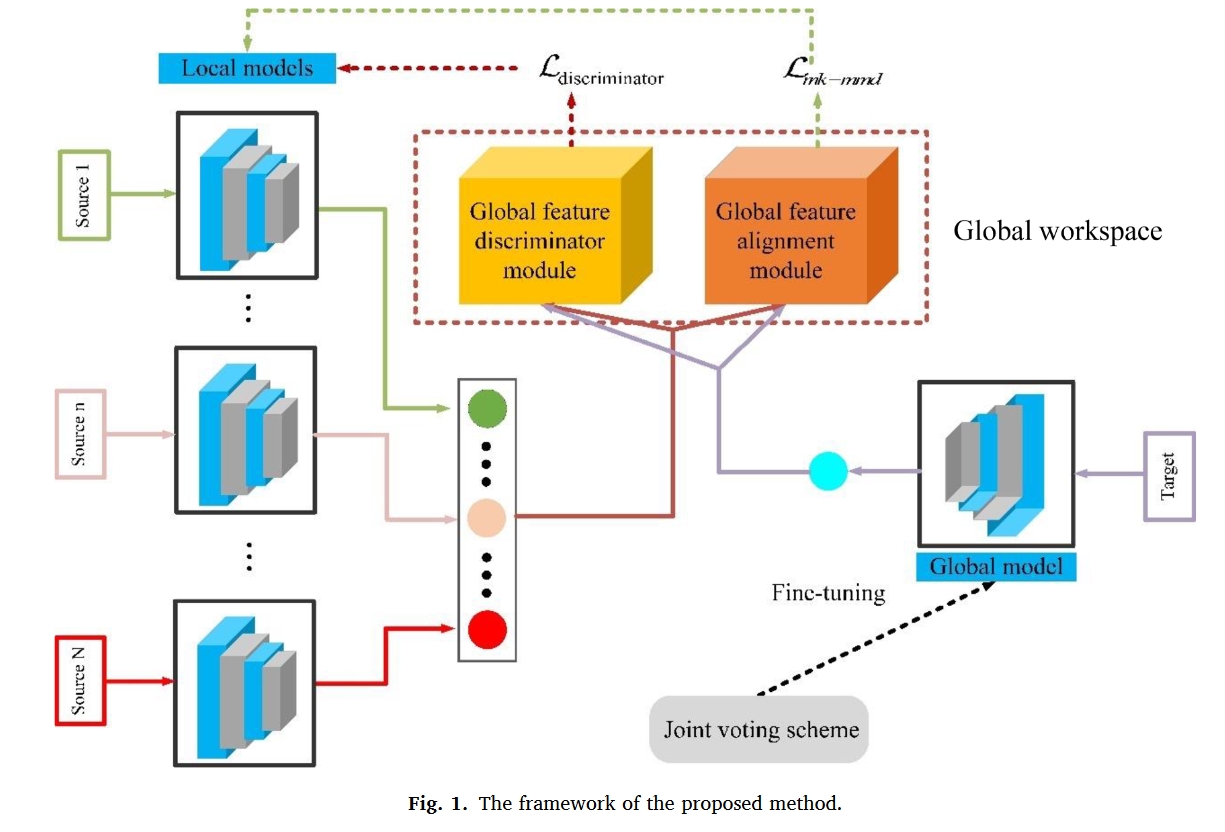
联邦特征对齐思想
在跨域故障诊断中,源域和目标域都监测具有多种故障模式的数据,显示出多模态数据结构的特点。因此,如果在全局空间中仅将源域和目标域的特征分布作为一个整体进行对齐,很容易造成错位,影响目标域的识别精度,甚至加剧联邦多源域自适应模型的负迁移现象。
在此基础上,根据所提出的联合特征对齐思想,设计了基于对抗性学习的全局特征鉴别器模块,以确保源域特征和目标域特征在边际概率分布上的相似性。
总之,所提出的联合特征对齐思想采用了两个模块来提取源域和目标域的域不变特征,包括基于多核MMD(MK-MMD)的全局特征对齐模块和基于对抗性学习的全局特征鉴别器模块。注意,与局部特征鉴别器相比,全局特征鉴别剂的使用可以显著降低通信成本。
在不失一般性的情况下,假设客户端n处的局部模型$C(n)$的特征提取器是$E(n)$,分类器是$F(n)$。并且给定输入样本x,对应的输出是$\hat{y} =E^{(n)} F^{(n)},(x)$。类似地,全局模型B的特征提取器是$E^B$,分类器是$F^B$。
全局特征鉴别器模块
全局特征鉴别器φ用于识别特征的来源。具体地,φ对$E^{(n)}$和$E^B$的输出特征集ft进行分类,将输入特征ft转换为相应的域标签$l$,并识别特征的来源。当$l=0$时,表示ft来自$D_s^n$,当$l=1$时,表示ft来自$D_t$。
φ相对于客户端n的优化过程描述为:
$$\begin{aligned}&\mathscr{L}{\mathrm{discriminator}}^{(n)}=\mathscr{L}\left(0,\varphi E^{(n)}\left(X{s}^{(n)}\right)\right)+\mathscr{L}\left(1,\varphi E^{\mathcal{B}}(X_{t})\right)\&\widehat{\varphi}=\underset{\varphi}{\operatorname*{argmin}}\mathscr{L}_{\mathrm{discriminator}}^{(n)}(\varphi,\widehat{E^{(n)}},\widehat{E^{\mathcal{B}}})\end{aligned}$$
其中$X^{(n)}_s∈D_s^{n}$和$X_t∈D_t$。
随着训练的进行,φ辨别特征ft的来源将变得越来越困难,这意味着$E(n)$提取的特征在边际概率分布方面与$E^B$提取的特征越来越相似。具体实现是通过最大化L^(n)^鉴别器来更新E^(n)^。
$$\widehat{E^{(n)}}=\operatorname*{argmax}{\hat{\varphi}}\mathscr{L}{\mathrm{discriminator}}^{(n)}(\widehat{\varphi},E^{(n)},\widehat{E^{B}})$$
全局特征对齐模块
为了进一步提取源域和目标域的域不变特征,我们设计了全局特征对齐模块。
近年来,MMD 被广泛应用于以源域和目标域差异最小化为优化目标的跨域特征适应方法中。与 MMD 相比,MK-MMD[31] 能更好地表示高维空间中的数据分布差异,提高模型的特征表示能力,因此采用 MK-MMD 来衡量源域和目标域之间的分布差异。
MKMMD的目标函数可以表示为:
$$\mathscr{L}{mk-mmd}^{(n)}=\frac15\sum{m=1}^5MMD_{sm}^2\left(E^{(n)}\left(X_s^{(n)}\right),E^B(X_t)\right)$$
最后,采用MKMMD损失的局部模型$E^{(n)}$的优化过程表示为:
$$\widehat{E^{(n)}}=\underset{E^{(n)}}{\operatorname*{argmin}}\mathscr{L}_{mk-mmd}^{(n)}\left(E^{(n)},\widehat{E^B}\right)$$
本地训练
因此本地训练的损失函数可以表示为:
$$\mathscr{L}\big(E^{(n)},F^{(n)}\big)=\mathscr{L}^{(n)}+\lambda\bigg(\mathscr{L}{mk-mmd}^{(n)}-\mathscr{L}{\text{discriminator}}^{(n)}\bigg)$$
其中$\mathscr{L}^{(n)}$为分类损失,$\mathscr{L}^{(n)}{discriminator}$为特征鉴别器损失,$\mathscr{L}^{(n)}{mk-mmd}$为MK-MMD损失。
联合投票方案
本研究旨在训练一个联合多源域自适应模型,以准确识别未标记的目标域。然而,未标记目标域样本的因素严重限制了全局模型提取更准确的特征表示。基于上述分析,本文提出了一种联合投票方案,以优化全局模型的特征提取过程,获得更准确的预测标签。具体而言,通过轮询局部模型对目标域样本的预测标签的一致性,使用获得的伪标签样本对全局模型进行微调,增强了全局特征鉴别器模块和全局特征对齐模块的特征对齐效果,最终准确预测了未标记目标域样本中的标签。
实际上就是MK-MMD需要标签,原来迁移学习中是使用了源域直接预测作为伪标签。这里就使用多个本地模型预测,选择标签占比最大的作为其伪标签。
实验
数据集
- Shandong University of Science and Technology dataset (SDUSTD)
- Jiangxi University of Science and Technology dataset (JXUSTD)
- the Paderborn University dataset (PUD)
| Task No. | Client #1 | Client #2 | Client #3 | Target |
|---|---|---|---|---|
| 1 | A1 | A2 | / | A3 |
| 2 | A1 | A3 | / | A2 |
| 3 | A2 | A3 | / | A1 |
| 4 | B1 | B2 | / | B3 |
| 5 | B1 | B3 | / | B2 |
| 6 | B2 | B3 | / | B1 |
| 7 | E1 | E2 | E3 | E4 |
| 8 | E1 | E3 | E4 | E2 |
| 9 | E1 | E2 | E4 | E3 |
| 10 | E2 | E3 | E4 | E1 |
对比方法
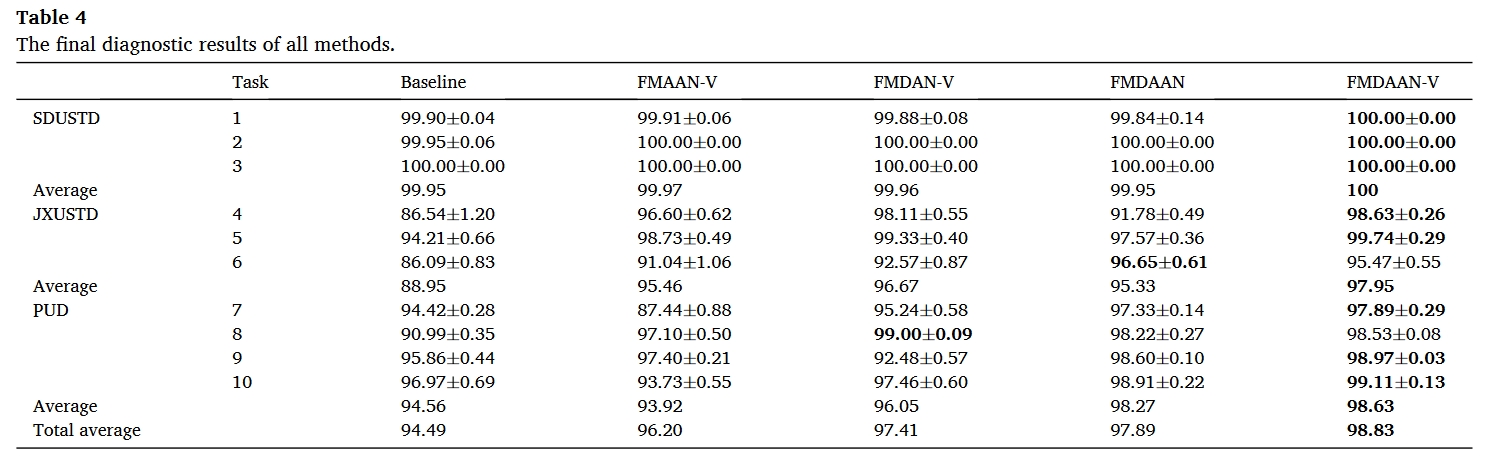
消融实验
Baseline:在不使用联合投票方案的情况下,利用基线方法来解决结构参数与所提出的框架相同的单源域故障诊断问题。
FMAAN-V (FMDAAN-V without using MK-MMD):FMAAN-V是一种联合多源域自适应方法,其与FMDAAN-V的唯一区别在于,FMAAN-V不使用MK-MMD来最小化不同源域和目标域之间的数据分布差异,并且所有其他信息都是一致的。
FMDAN-V (FMDAAN-V without using feature discriminator):FMDAN-V是一种联合多源域自适应方法,它与FMDAAN-V的唯一区别在于没有使用特征鉴别器,并且所有其他信息都是一致的。
FMDAAN(The proposed method without using joint voting scheme):FMDAAN 是一种联合多源领域适应方法,它与 FMDAAN-V 的唯一区别是,FMDAAN 不使用联合投票方案来微调全局模型,而其他所有信息都是一致的。
KDMUMDAN:Mech Syst Signal Process 2023
CWTWAE:Knowl Based Syst 2021
DWFA-L1:ICSMD 2021
DWFA:IEEE Trans Instrum Meas 2022
实验结果
| Task | FMDAAN-V | KDMUMDAN | CWTWAE | DWFA-L1 | DWFA |
|---|---|---|---|---|---|
| 1 | 100.00+0.00 | 100.00士0.00 | 100.00士0.00 | 99.76士0.22 | 100.00士0.00 |
| 2 | 100.00+0.00 | 100.00士0.00 | 100.00士0.00 | 99.90士0.05 | 99.69士0.11 |
| 3 | 100.00士0.00 | 100.00士0.00 | 99.88土0.12 | 99.43士0.33 | 99.93土0.06 |
| 4 | 98.63土0.26 | 98.92土0.38 | 98.65土0.30 | 98.93士0.21 | 97.98土0.37 |
| 5 | 99.74士0.29 | 99.45土0.22 | 99.39士0.18 | 99.36士0.09 | 99.84士0.08 |
| 6 | 95.47土0.55 | 97.48+0.59 | 96.40士0.18 | 95.210.78 | 96.06土0.47 |
| 7 | 97.89士0.29 | 99.65+0.16 | 99.35土0.12 | 97.56土0.28 | 97.81土0.25 |
| 8 | 98.53土0.08 | 99.04+0.12 | 98.51土0.15 | 98.03士0.40 | 97.22土0.30 |
| 9 | 98.9710.03 | 99.92+0.09 | 99.66土0.09 | 99.10土0.16 | 98.84土0.17 |
| 10 | 99.11土0.13 | 98.85 0.46 | 100.00+0.00 | 97.46士0.55 | 99.39 0.21 |
| Avg. | 98.83 | 99.33 | 99.18 | 98.47 | 98.68 |
总结
总的来看,本文是把GAN和MK-MMD以及联邦学习融合到了一起。这里MK-MMD第二次提到,应该重视。
主要是使用GAN中鉴别器的思想来改变多个源域的分布使之一致。