期刊: IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT (IF:5.6)
引言
风力涡轮机故障重要,经常发生。有必要对风力发电机进行状态监测与故障诊断。
传统的故障诊断方法一般包括三步:
- 从采集的故障信号中提取故障特征
- 对故障特征的降维
- 通过分类器进行故障诊断
传统的故障诊断研究需要复杂的过程,如降噪、滤波和特征提取。该过程依赖于专业背景知识,耗费大量人力,提取特征的好坏直接影响故障诊断的效果,这大大增加了在复杂条件下面对轴承故障诊断时手动设计特征的难度。
介绍深度学习算法,NN,GAN 等。总之,深度学习模型由于其特点,在故障识别和诊断方面具有显著优势。
目前,深度学习模型在风机故障诊断领域的应用仅限于通过从一维信号中提取故障特征来诊断和识别故障位置。(??有点疑问,不是很多都是二维的?)然而,在实际操作中,一个部件有多个可能的故障位置,在风力涡轮机轴承故障诊断中,多传感器通常用于监测多个位置的故障。因此,本文在之前研究的基础上,采用图像融合的方法对多传感器数据的故障特征进行融合,然后利用深度学习模型实现了基于多源信号的风机轴承多位置故障诊断。为了改善GAN训练的不稳定性,本文将VAE和GAN相结合,以提高模型故障样本的生成效果。这种方法可以有效避免风机故障造成的长期停机,并在一定程度上降低风机的运行和维护成本。本文贡献:
- 为了更有效地挖掘故障特征,我们将样本集中的一维振动信号转换为二维信号。利用小波变换对多源二维振动信号进行融合,可以实现风机的多类别故障诊断。
- 针对故障诊断中样本不足和不平衡的问题,我们提出了 CVAE-GAN 模型来补充不平衡和小数据集中的样本数量。首先,引入 VAE 编码器作为 GAN 生成器的前端,通过对故障样本进行编码来提高模型训练的稳定性。然后,引入样本标签作为编码器、生成器和判别器的输入,以提高模型的训练效率。最后,在样本不平衡和不充分的情况下,我们可以获得分类器对风机故障的识别精度。
方法-CVAE-GAN模型
变分自编码器
变分自编码器(Variational Auto-Encoders,VAE)作为深度生成模型的一种形式,是由 Kingma 等人于 2014 年提出的基于变分贝叶斯(Variational Bayes,VB)推断的生成式网络结构。
与传统的自编码器通过数值的方式描述潜在空间不同,它以概率的方式描述对潜在空间的观察,在数据生成方面表现出了巨大的应用价值。
自编码器的思想:
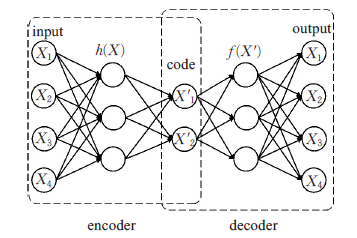
通过训练,输入数据X最终被转化为一个编码向量X’, 其中X’的每个维度表示一些学到的关于数据的特征,而X’在每个维度上的取值代表X在该特征上的表现。随后,解码器网络接收X’的这些值并尝试重构原始输入。
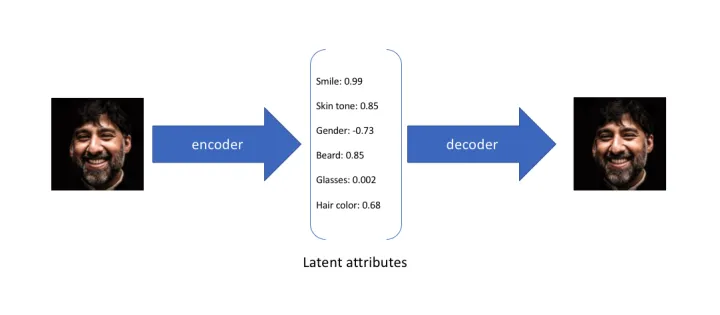
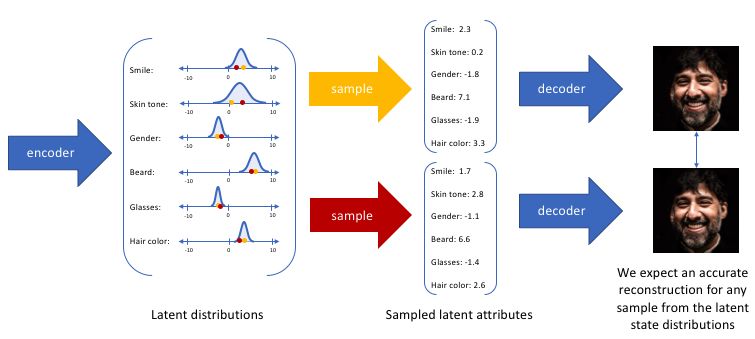
例如:假设任何人像图片都可以由表情、肤色、性别、发型等几个特征的取值来唯一确定,那么我们将一张人像图片输入自动编码器后将会得到这张图片在表情、肤色等特征上的取值的向量X’,而后解码器将会根据这些特征的取值重构出原始输入的这张人像图片。
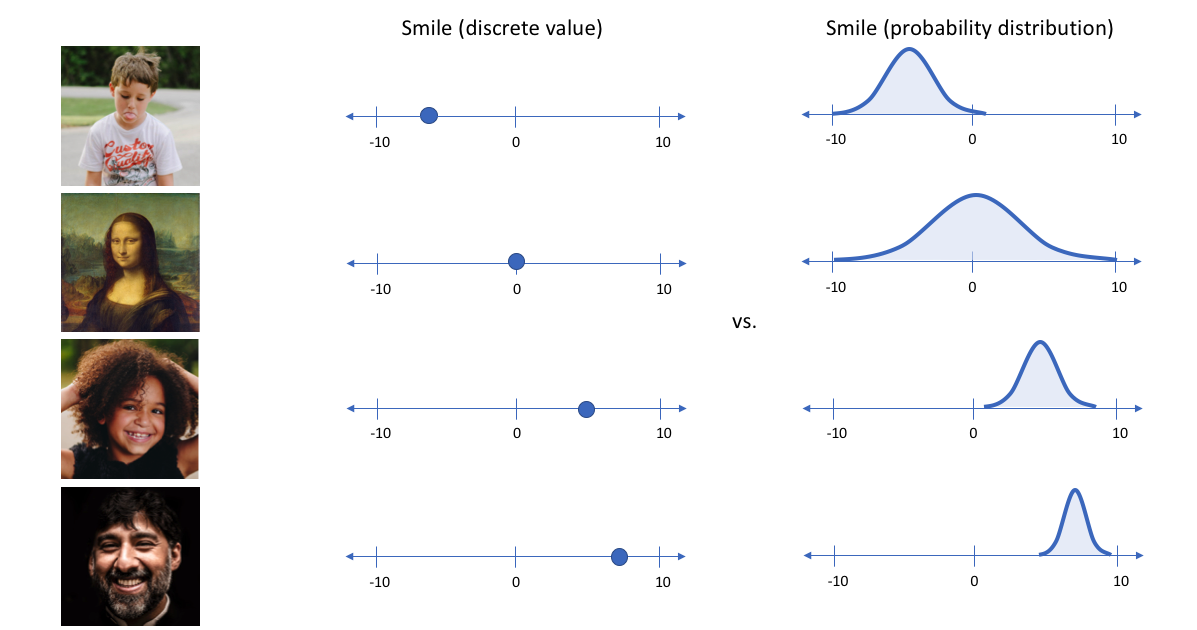
上面的例子中,对于每一个特征,都是直接使用一个特定的值来表示。但在实际情况中,我们可能更多时候倾向于将每个潜在特征表示为可能值的范围。例如,对于蒙娜丽莎的照片,并且将其微笑作为一个特征。那么现实中我们可能更加常见的表示为她微笑的概率为百分之多少。而不是她微笑了,或没微笑。
而变分自编码器便是用“取值的概率分布”代替原先的单值来描述对特征的观察的模型,如下图的右边部分所示,经过变分自编码器的编码,每张图片的微笑特征不再是自编码器中的单值而是一个概率分布。
通过这种方法,我们现在将给定输入的每个潜在特征表示为概率分布。当从潜在状态解码时,我们将从每个潜在状态分布中随机采样,生成一个向量作为解码器模型的输入。
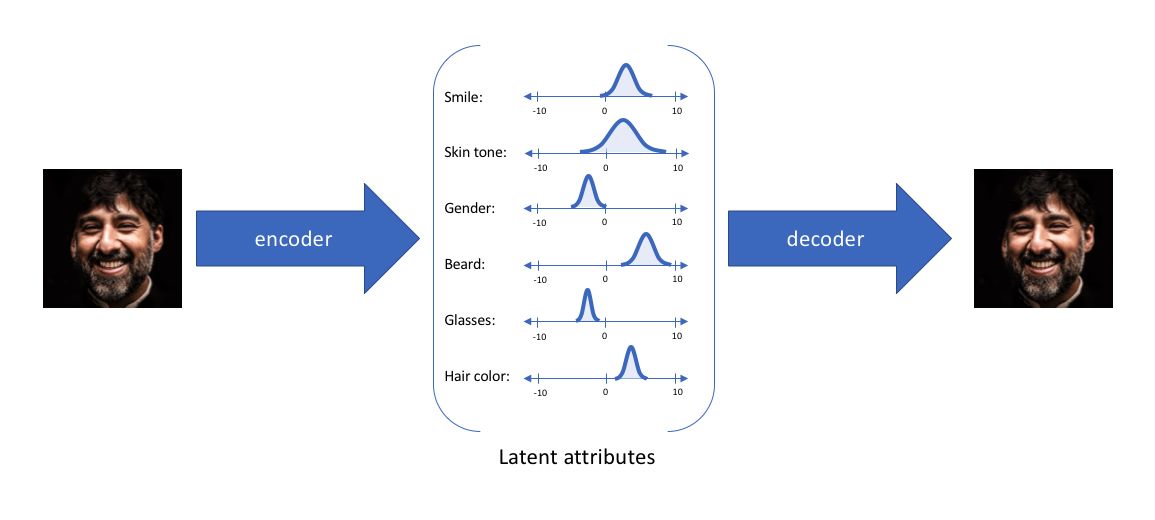
通过上述的编解码过程,我们实质上实施了连续,平滑的潜在空间表示。
对于潜在分布的所有采样,我们期望我们的解码器模型能够准确重构输入。因此,在潜在空间中彼此相邻的值应该与非常类似的重构相对应。
下面式变分自编码器的基本结构:
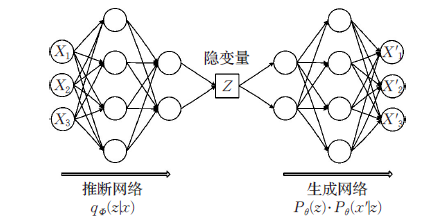
如上图所示,与自动编码器由编码器与解码器两部分构成相似,VAE利用两个神经网络建立两个概率密度分布模型:一个用于原始输入数据的变分推断,生成隐变量的变分概率分布,称为推断网络;另一个根据生成的隐变量变分概率分布,还原生成原始数据的近似概率分布,称为生成网络。
给定输入数据X的情况下,变分自动编码器的推断网络输出的应该是Z的后验分布p(z|x)。 但是这个p(z|x)后验分布本身是不好求的。所以有学者就想出了使用另一个可伸缩的分布q(z|x)来近似p(z|x)。通过深度网络来学习q(z|x)的参数,一步步优化q使其与p(z|x)十分相似,就可以用它来对复杂的分布进行近似的推理。
为了使得q和p这两个分布尽可能的相似,我们可以最小化两个分布之间的KL散度:
$min KL(Q(z|x)||p(z|x))$
Generative Adversarial Network
GAN模型由一个生成器和一个鉴别器组成。生成器是GAN的核心部分,鉴别器的存在使生成器能够通过对抗性训练生成高质量的图像。GAN的概念是一个两人游戏,其中游戏双方的利益之和是常数。如果一方赢了,另一方一定输了。GAN零和博弈的双方是生成器和鉴别器。
GAN的训练方法是在单独的迭代中训练生成器和鉴别器,以便生成器和鉴别器可以通过反向传播达到纳什均衡,即可以最小化两个模型的损失函数。GAN的目标函数如下:
$\mathop{min} \limits_{G} \mathop{max}\limits_{D} V(D, G) = E_{x \sim p_{data}(x)}[logD(x)]+E_{z \sim p_{z}(z)}[log(1-D(G(z)))]$
其中,D(x)是鉴别器确定x是真实样本的概率,D(G(z))是鉴析器确定生成的样本G(z,z)是真实样本,G(z)是生成器的生成图像,z是生成器的输入。
生成器将随机噪声变量 z 输入构建的样本空间 pz,拟合真实样本 x 的分布$p_{data}$,输出生成样本 x′ 的分布 $p_g$。生成器的目的是使生成的样本分布尽可能接近真实样本分布,因此生成器训练的损失函数为
$L_G=E_{z \sim p_{z}(z)}[log(1-D(G(z)))]$
判别器将真实样本分布 $p_{data}$和生成的样本分布 $p_g$ 作为输入。判别器的输出是被判别样本的概率值,即产生一个 0-1 范围内的直接标量。判别器的目的是尽可能识别输入样本是真实样本还是生成样本,如果输入是真实样本,则判别器的输出标记为 1;如果输入是生成样本,则判别器的输出标记为 0。判别器训练的损失函数为
$L_D = E_{x \sim p_{data}(x)}[logD(x)]+E_{z \sim p_{z}(z)}[log(1-D(G(z)))]$
CVAE-GAN Model
针对模型故障特征的学习能力,本文将VAE和GAN相结合,提出了CVAE-GAN模型。在GAN[27]的基础上,引入VAE的编码器作为GAN生成器的前端网络。为了提高模型的训练效率和稳定性,在编码器、生成器和鉴别器的输入中添加了类别标签,以改进多类别场景中生成数据的目标定位。最后,利用鉴别器实现了多类故障样本。CVAE-GAN模型的结构如图1所示。
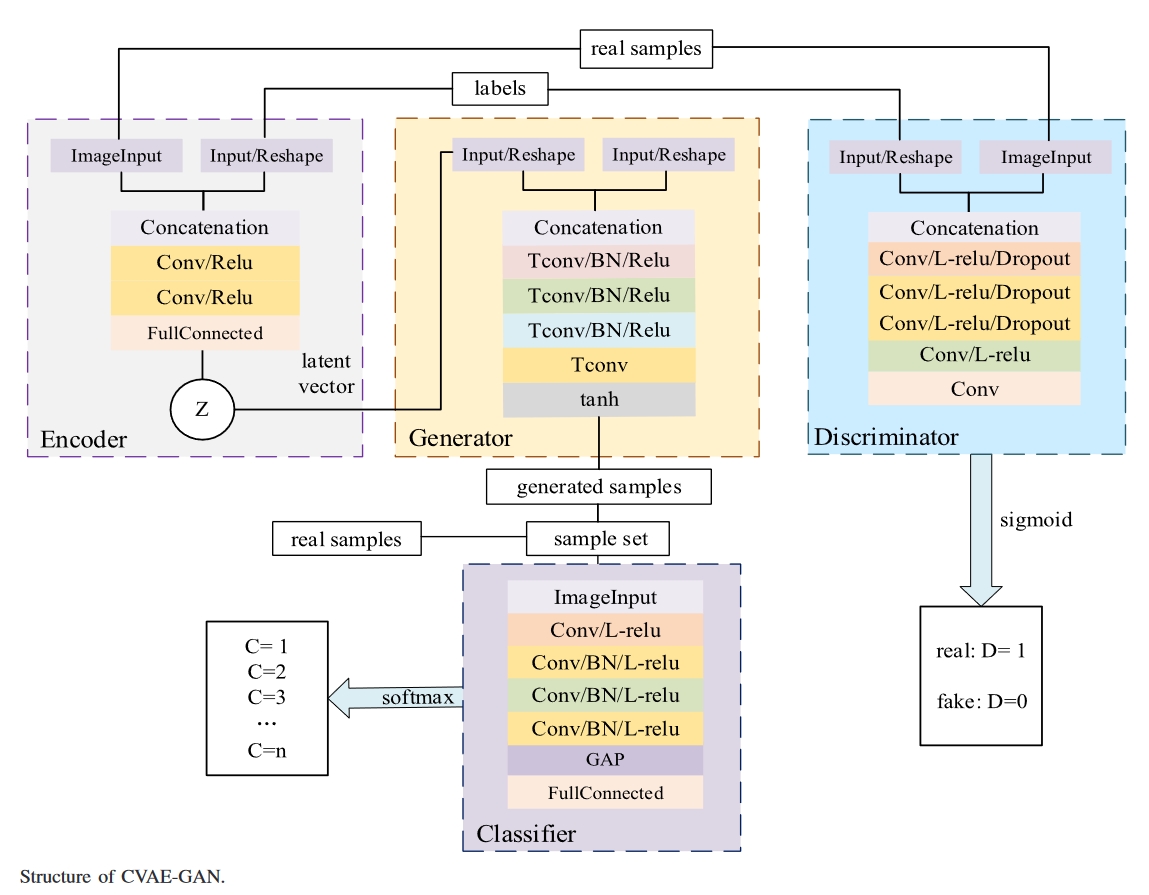
CVAE-GAN有四个部分:
- encoder:编码器的学习目标是使潜在向量的分布符合预期,因此选择KL散射函数作为目标函数。
- generator:生成器学习的目标是使生成的样本尽可能接近真实样本。
- discriminator:鉴别器的学习目标是使实际样本输出收敛到1,生成的样本输出收敛为0。
- classifier:分类器的学习目标是区分不同类别的错误样本。
编码器、生成器和鉴别器负责故障样本生成和真实/虚假识别;
分类器负责区分不同类别的故障数据。
下面是上面四个部分的目标函数:
$L_E=\frac{a}{b} \sum \limits ^J_{j=1} (1+log(\sigma^2_j)-\mu^2_j-\sigma^2_j)$
$L_G=E_{z \sim p_{z}(z)}[log(1-D(G(z)))]$
$L_D = E_{x \sim p_{data}(x)}[logD(x)]+E_{z \sim p_{z}(z)}[log(1-D(G(z)))]$
$L_C=E_{x \sim p_{data}(x)}[logC(x)]$
其中,$L_E$、$L_G$、$L_D$和$L_C$分别是CVAEGAN模型中编码器、生成器、鉴别器和分类器的损失函数,C(x)是分类器正确识别x故障类型的概率。
实验
样本转化
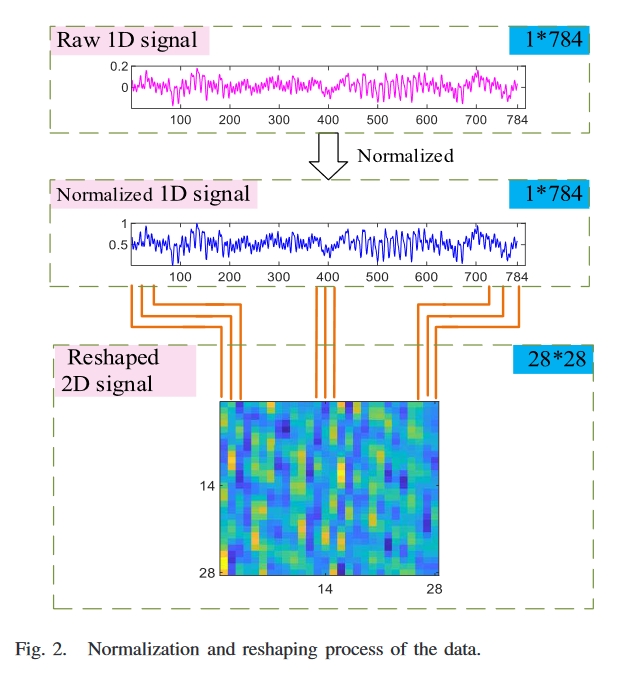
数据集中的振动信号是一维时间序列信号。由于抑制过拟合会增加一维卷积神经网络设计的难度[30],我们选择将一维时序信号转换为二维信号,通过二维卷积网络进行故障样本扩展和故障诊断。根据轴承转速和采样频率,计算出轴承每旋转一周可采样约411个点;选择大约两个旋转周期的784个采样点作为图像格式为28×28的二维图像信号的像素点,以充分利用卷积网络中的故障特征,避免由于图像规格过大而增加单位批次的训练时间。如图2所示,在构建样本之前,需要对一维时域信号进行归一化。
实验步骤
- 将两组归一化的一维时域信号处理为二维信号。
- 通过小波变换将两组二维信号重构为一组二维信号。
- 构造不平衡样本集和小集,划分训练集和测试集。
- 通过训练集训练CVAE-GAN模型,并更新网络参数。
- 将真实样本输入编码器以获得相应的后验分布,并通过从标准正态分布与相应的正态分布相结合的采样来生成隐藏变量。
- 生成器基于隐藏变量获取生成的样本,生成的样本与真实样本混合并输入到鉴别器。同时,利用混合数据对鉴别器进行训练,使生成器和鉴别器达到博弈平衡并保存模型参数。
- 故障样本由CVAE-GAN模型补充,生成的样本和真实样本形成各种样本集。样本集被输入到分类器以输出故障诊断结果。故障诊断过程如图4所示。
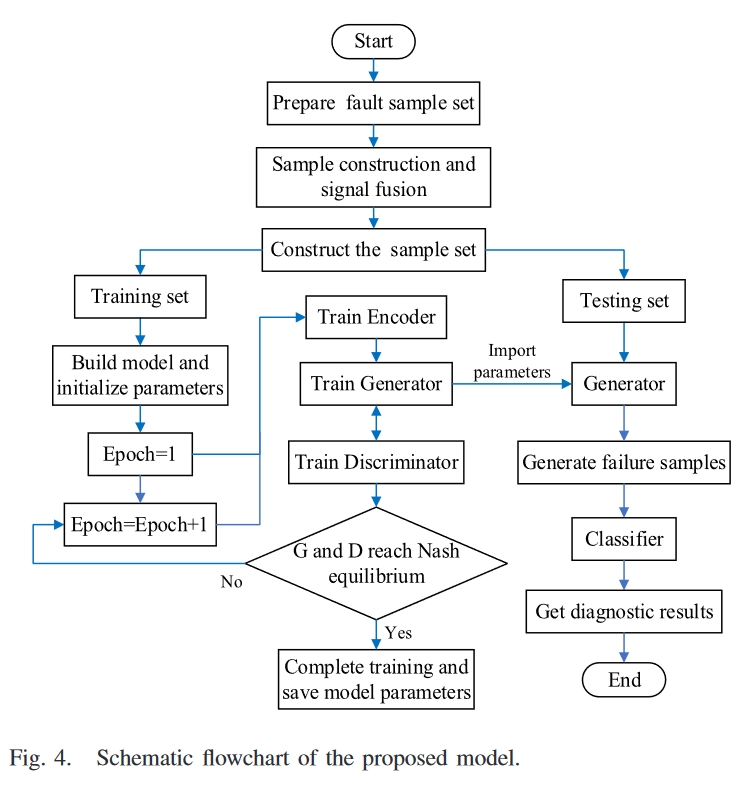
对于样本不均匀的问题,该文使用CVAE-GAN模型在真实故障样本的基础上生成新的样本,以补充不平衡故障样本的数量,从而使每个故障类别的样本数量平衡。
实验结果
不平衡样本集的实验分析
| sample set | imbalanced sample classes |
|---|---|
| 1 | |
| 2 | 2,12 |
| 3 | 3,7,13,15 |
| 4 | 4,6,9,11,16,18 |
| 5 | 2,5,8,10,11,14,17,19 |
case1:平衡类中的样本数为2000,不平衡类中样本数为1000。
case2:平衡类中的样本数为2000,不平衡类中样本数为800。
case3:平衡类中的样本数为2000,不平衡类中样本数为600。
| set1 | set2 | set3 | set4 | set5 | |
|---|---|---|---|---|---|
| case1 | 99.47 | 99.61 | 99.63 | 99.55 | 99.42 |
| case2 | 99.47 | 99.42 | 99.42 | 99.34 | 99.58 |
| case3 | 99.47 | 99.29 | 99.37 | 98.16 | 99.32 |
小样本集的实验分析
| sample set | the number per fault class | the total number of samples |
|---|---|---|
| 6 | 1000 | 19000 |
| 7 | 900 | 17100 |
| 8 | 800 | 15200 |
| 9 | 600 | 11400 |
| 10 | 400 | 7600 |
| set1 | set2 | set3 | set4 | set5 | |
|---|---|---|---|---|---|
| case1 | 99.47 | 99.61 | 99.63 | 99.55 | 99.42 |
| case4 | 99.18 | 99.47 | 99.21 | 96.63 | 99.29 |
| case5 | 99.11 | 99.18 | 99.45 | 95.95 | 99.34 |
| case6 | 95.42 | 94.89 | 94.69 | 94.76 | 95.24 |
方法比较
| Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | Set 6 | Set 7 | Set 8 | Set 9 | Set 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| GAN+NN | 78.92% | 69.42% | 78.89% | 84.21% | 94.71% | 93.68% | 84.16% | 78.92% | 73.66% | 68.47% |
| GAN+SAE | 85.22% | 90.26% | 87.39% | 87.71% | 79.34% | 83.89% | 73.29% | 82.45% | 80.61% | 66.61% |
| CVAE-GAN | 99.47% | 99.61% | 99.63% | 99.55% | 99.42% | 99.39% | 99.45% | 99.37% | 95.92% | 94.79% |
| ACGAN | 93.87% | 93.89% | 91.82% | 93.39% | 95.58% | 95.16% | 94.95% | 95.16% | 92.74% | 91.68% |